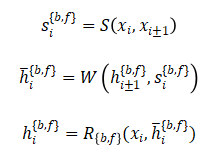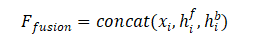作者:龚帅斌
引言
随着技术的不断发展,如今网络上的视频图像质量相比以前大幅提高,高清的4K、8K视频开始普遍出现。但是以前大量的视频与图像仍然存在,这些低质量、低分辨率的大量视频与图像如何加以有效利用,是一个有待解决的技术问题。
超分辨率(VSR)技术为解决各种原因下的低分辨率问题而提出,可将低分辨率(Low-Resolution,LR)影像,重建成高分辨率(High-Resolution,HR)影像,即视频分辨率的提升。目前超分辨率技术已有广泛的应用,如医学影像重建、人脸图像重建、远程传感、全景视频、无人机监控、超高清电视等。
本文介绍一种通用、效率、轻量的VSR模型BasicVSR[1],是当前视频超分辨率领域研究的baseline。
效果展示
图1展示了泰坦尼克号电影片段超分辨率增强前后的对比,竖线左侧为高分辨率图像。视频已压缩,因此展示效果比不上实际输出的结果。

图1 超分辨率效果展示
论文介绍
BasicVSR算法模型由来自南洋理工大学S-Lab的Kelvin C. K. Chan提出,论文收录于CVPR2021。作者将VSR任务分成了4个模块:帧间信息的传播模块:解决在提取特征时,如何利用序列帧信息的问题特征对齐模块:对齐特征图以更好地融合信息,提升重建精度特征融合模块:融合所有得到的特征信息,后接上采样模块
上采样模块:利用融合特征信息,重建高分辨率图像
01、帧间信息传播模块
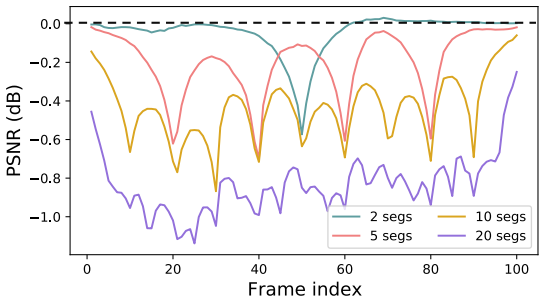
与单幅图像不同,视频中当前帧可利用相邻多帧图像进行超分辨率重建,拥有更多的可参考信息,有更高的重建质量上限,同时在特征提取时,如何利用这些序列帧信息,成为视频超分辨率中必须解决的问题。在此之前,使用视频序列信息的主要方法为滑动时间窗口,网络每次处理的是整个序列的局部信息,这和人们的常规认知相符:距离当前帧较近的帧比较远的帧有着更多的可利用信息。但是滑动窗口的方法,直接放弃了距离较远的帧,导致重建时信息缺失。作者做了个实验,将一个长输入序列分为K段,输入到网络中,重建结果如图2所示:
图2 分成K段的视频重建结果
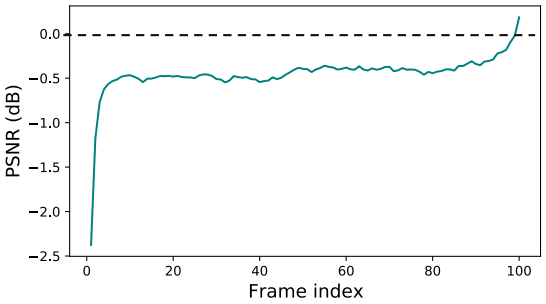
其中横轴为帧序号,纵轴PSNR为峰值信噪比,衡量重建后的图片与原始图片之间的相似程度的一个指标,越高越好。实验表明,分段数越少,表现力越好。越大的感受野越有利于视频的超分辨率重建,同时证明较远的帧信息对于当前帧重建的重要性,采用较长的帧序列作为输入的必要性,通过滑动窗口选取感受野有较大的局限性。解决上述问题有一个简单的方法,直接将一整段视频序列按时序全部输入至网络。这样的输入方式得到图3所示的重建结果:
图3 整段输入的视频的重建结果
可以看到,视频前几帧的效果较差,最后几帧的效果很好。这是由于视频的前几帧可利用的帧信息太少,随着时间推移,可利用的信息越来越多,最后几帧几乎可以利用整个视频序列所有帧的特征信息。这种方法的局限性在于无法解决视频前几帧重建效果较差的问题。
为解决这个问题,BasicVSR利用视频帧序列的方法是建立一个前向分支,一个后向分支,让输入分别从头到尾和从尾到头不断进行特征提取。对于每一个当前帧xi,其本身与其前后邻帧xi-1、xi+1的双向循环特征提取结构如图4所示:
其中Ff与Fb分别为网络的前后向分支,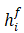 、
、 分别为当前帧的特征信息,输入分别为当前帧xi、前后邻帧xi±1、前后邻帧的特征图
分别为当前帧的特征信息,输入分别为当前帧xi、前后邻帧xi±1、前后邻帧的特征图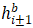 。
。
输出的特征信息既作为下一帧的输入,也作为输出给到特征融合与上采样阶段,用于重建图像。
02、特征对齐模块
如图5所示,超分辨率网络的输入为视频帧序列,而相邻帧之间的画面内容一般存在一定的移动,因此将未对齐的图像作为输入时,特征利用与融合信息存在障碍,重建效果较差。

图5 视频帧序列
业界早期的对齐方式大多都只是图像级对齐,这相比不做对齐有一定的重建效果提升。而在作者的另一篇文章,视频超分辨率中的可变形对齐[2]中证明,特征级对齐相比图像级对齐有着更多的性能提升。因为图像级对齐依赖准确的光流估计,较低的光流精度会导致对齐图像的重影,带来重建精度下降。特征对齐模块结构如图6所示:

其中S是光流估计模块,为预训练过的SPyNet[3]网络,输入为当前帧xi与邻帧xi±1,输出为当前帧的前后向光流估计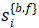 ;
;
W是特征对齐模块,输入为当前帧的前后向光流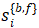 与当前帧邻帧的前后特征图
与当前帧邻帧的前后特征图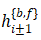 ,输出为与当前输入xi对齐后的特征图
,输出为与当前输入xi对齐后的特征图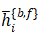 ;
;
 是特征校正模块,输入为当前帧和对齐后的前后向特征图,输出为当前帧的前后向特征图
是特征校正模块,输入为当前帧和对齐后的前后向特征图,输出为当前帧的前后向特征图 。
。
03、特征融合模块
在特征融合之前,经过帧序列的特征提取、帧序列的特征对齐与特征校正,最终得到当前帧的前后向特征图,加上当前帧一起作为融合模块的输入,输出为融合后的特征图。BasicVSR在特征融合阶段将当前帧与其前后向特征图进行了concat,公式为:
04、上采样模块
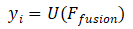
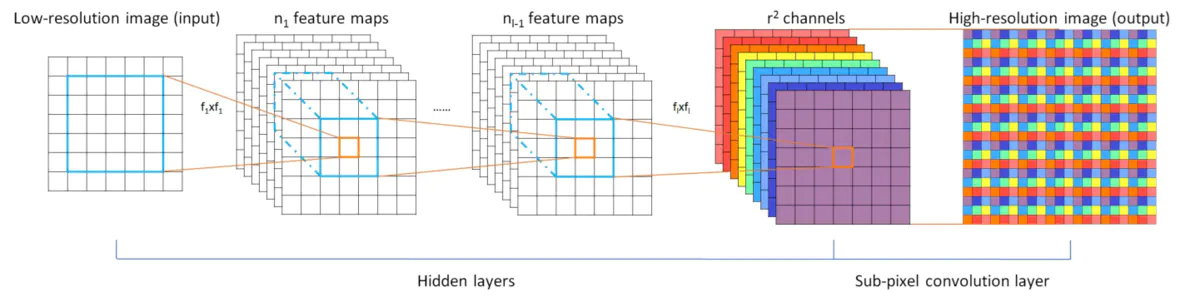
其中U表示上采样模块,包括用于特征提取的多个普通卷积层,和用于上采样的一个亚像素卷积层。输入为特征融合结果Ffusion,输出为重建得到的当前帧的HR图像。对于亚像素卷积的理解问题,像素为图像的最小单位,而亚像素指的是微观上两个像素之间的区域,硬件无法表示,但软件可以近似地计算出来。亚像素卷积又叫像素重组(Pixel-Shuffle),将低分辨的特征图,通过一系列卷积进行特征提取后,在重组前形成了r2个通道的特征图(r为上采样倍数)。然后将r2个通道的特征图组合为(w×r,h×r)的采样结果。训练时会调整r2个通道的权重,优化重建的效果。
图7 亚像素卷积过程示意图
总结
本文介绍的BasicVSR不仅是一个轻量且高效的视频超分辨率框架,它更大的价值在于某种程度上可作为视频超分辨率研究的基准。例如在帧间信息传播模块中,在BasicVSR的前向分支基础上,引入后向分支的特征,让每一帧的特征对齐都能利用过去和未来的特征信息;再例如在BasicVSR的特征融合阶段,添加额外的特征提取模块,更好地融合当前帧与其相邻帧的特征信息。这两点改进便是后来更进一步的IconVSR,可在一定程度上解决BasicVSR中因为遮挡、边界等问题造成的重建误差。
参考文献
[1] Chan, K.C., Wang, X., Yu, K., Dong, C., & Loy, C.C. (2021). BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 4945-4954.[2] Chan, K. C., Wang, X., Yu, K., Dong, C., & Loy, C. C. (2021). Understanding Deformable Alignment in Video Super-Resolution. Proceedings of the AAAI Conference on Artificial Intelligence, 35(2), 973-981. Retrieved from https://ojs.aaai.org/index.php/AAAI/article/view/16181[3] Ranjan, A., & Black, M.J. (2017). Optical Flow Estimation Using a Spatial Pyramid Network. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2720-2729.