
高效数据治理与资源构建,助力政府和企业数字化转型
产品架构

核心功能

以标准化手段灵活构建清晰的分 实现跨系统,跨部门数据的汇聚, 高效自动化地完成质量检测、问 灵活创建数据质量检测规则,第
层式资产数据目录 统一监控 题修复、数据审核 一时间定位系统脏数据

标签与群组体系建立,洞察客户 数据安全与权限管控,平台系统 实现跨区域,跨系统,跨部门数 灵活配置数据API服务,构建全
特征,建立数据运营体系 配置与操作审计 据的汇聚 面的数据共享能力
产品优势

具备广泛数据类型接入能力,支持 基于规则的脏数据自动化检测能 以数据标签、数据质量管控为全
结构化与非结构化多源异构数据采 力,同时具有手工交互和基于脚 生命周期资产沉淀的有效手段,
集,兼容主流数据库并可按需定制 本的半自动化修复能力 实现标准化数据资源编目功能

建立分层分级数据共享机制,规范 支持MPP与糊仓一体架构,大、 提供安全可靠的国产信创解决
多方权限操作范围,支持共享中灵 小集群与单机化部署方式可为 方案,具备与国产主流服务器
活配置脱敏字段 用户带来更多灵活选择 中间件、软件系统的深度兼容
应用场景

数字化政府治理 企业智改数转 点亮数字生活
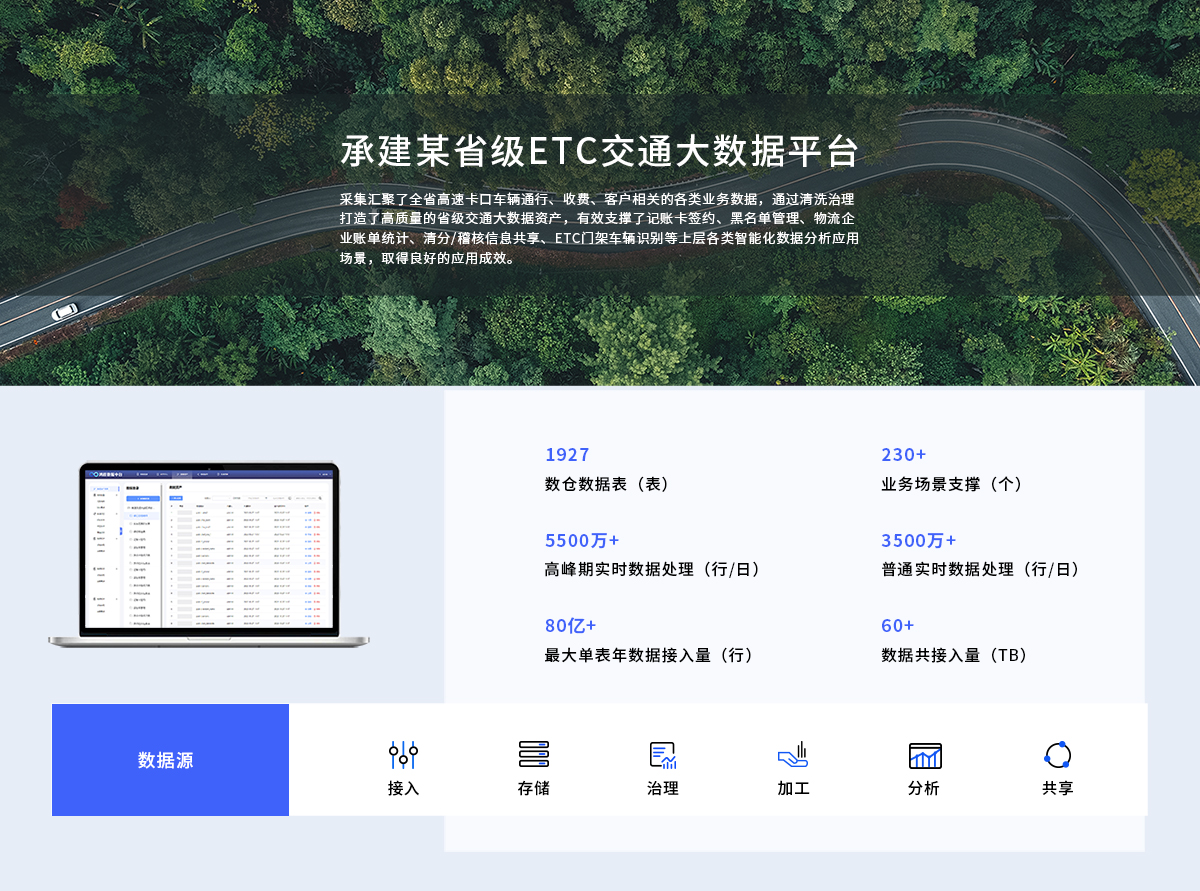
应用案例