作者:于辉、麦丞程
短文本主题模型
1.1 应用价值
随着互联网信息技术的广泛应用和移动智能终端的普及,短文本成为日常生活中重要的信息来源,同时也是众多互联网应用中信息传递的重要载体,比如微博、商品评论、新闻推送等。从这些短文本中挖掘潜在的主题对于关键词挖掘、文本表征、用户兴趣分析、新兴主题检测、短文本分类等基于内容的分析任务来说十分重要。
1.2 难点问题
传统的主题建模方法概率潜在语义分析模型(pLSA)和潜在狄利克雷分配模型(LDA)基于文档层级的单词共现模式进行建模,但是相同词汇对在短文本语料上共现的频率非常稀疏,这些方法显然不适用于短文本的主题建模。同时,现有主题模型大都通过“主题-单词”来描述主题,没有利用短文本内部的构成成分,而主题实际上由许多不同方面组成的,比如地点、人名、组织、核心词和背景词等等。所以,短文本主题建模需要考虑以下两个难点问题:为了解决上述问题,本文将介绍一种基于狄利克雷多项式混合(DMM)的短文本主题模型TSSE-DMM,该模型通过将主题成分进行细分(Topic Subdivision, TS)以及使用语义增强(Semantic Enhancement, SE)的方式,实现无监督地在大量短文本语料上分析出短文本的主题,以及与主题相关的地点、对象和关键词等信息,极大增强了短文本主题模型的可解释性。
LDA与DMM模型的背景简介
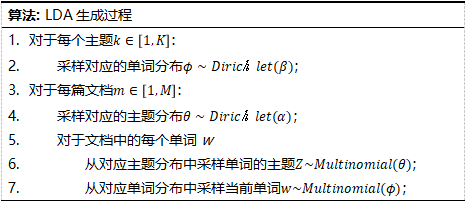
LDA是一个用来对文本的生成过程进行建模贝叶斯模型,其基本思想是文档被表示为潜在主题的随机混合,每个主题都对应词项上的一个概率分布。“文档-主题”分布和“主题-单词”分布都服从于多项式分布,并且都采用多项式分布的共轭分布狄利克雷分布作为先验分布;与LDA不同,DMM认为语料集中的每篇文档只有一个采样自全局主题分布的主题,且文档中的每个单词相互独立,并采样自同一个“主题-单词”分布。LDA与DMM概率图模型可用下图表示。

其中,M代表文档数,N代表每篇文档中的单词数,K代表设定的主题数, w是文档中的单词,其对应的主题分配为Ζ。
LDA文档下的主题分布和主题下的单词分布分别表示为θ和ϕ,分别服从于参数为α和β的狄利克雷先验分布。LDA模型的生成过程可以表示为:
DMM全局主题分布θ和每个主题对应的单词分布ϕ都是一个多项式分布,分别服从于参数为α和β的狄利克雷先验分布。DMM模型的生成过程可以表示为:
LDA和DMM常用吉布斯采样(Gibbs Sampling)算法进行模型推断。
基于成分细分和语义增强的主题模型—TSSE-DMM
3.1 引入词性特征细分短文本主体结构
与DMM一样,TSSE-DMM假设每篇文档d只有一个主题z,采样自全局主题分布p(z=k)= 。每个主题z由多个特征q描述,可以根据具体语料和用户需求定义主题相关的特征集Q={q|q=0,...,N|Q|}。
。每个主题z由多个特征q描述,可以根据具体语料和用户需求定义主题相关的特征集Q={q|q=0,...,N|Q|}。
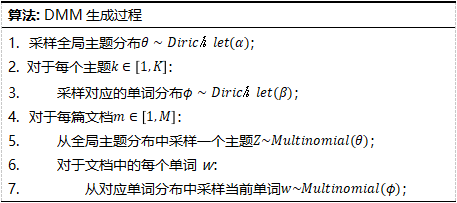
默认情况下Q={0,1,2},分别代表与每个主题相关的地点、对象和关键词三个特征。TSSE-DMM从863词性标注集中选择了一些标签来引入词性特征:对于词性质{ns}(地点名词),单词对应的词性特征为地点,q=0;对于词性{ni,nh,j}(机构名、人名、缩写),单词对应的词性特征为对象,q=1;对于词性{n,nz,v,a,i}(一般名词、其他专有名词、动词、形容词、习语),另外引入一个开关变量决定该单词是关键词还是背景单词,若该单词属于关键词,则对应的词性特征为关键词,q=2;否则,从全局背景单词分布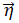 中采样该单词。TSSE-DMM短文本语料的生成过程描述如下:
中采样该单词。TSSE-DMM短文本语料的生成过程描述如下:

对于qw∉{0,1}的单词w,作为开关变量sw的先验参数λw计算方法如下:
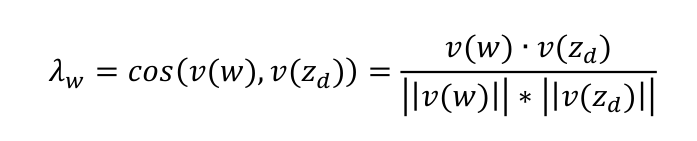
其中,v(w)是单词w的词嵌入向量,v(zd)是主题zd的每个特征分布下概率值最高的前N个单词的词嵌入向量的平均值。
3.2 基于语义相似度的短文本主题语义增强
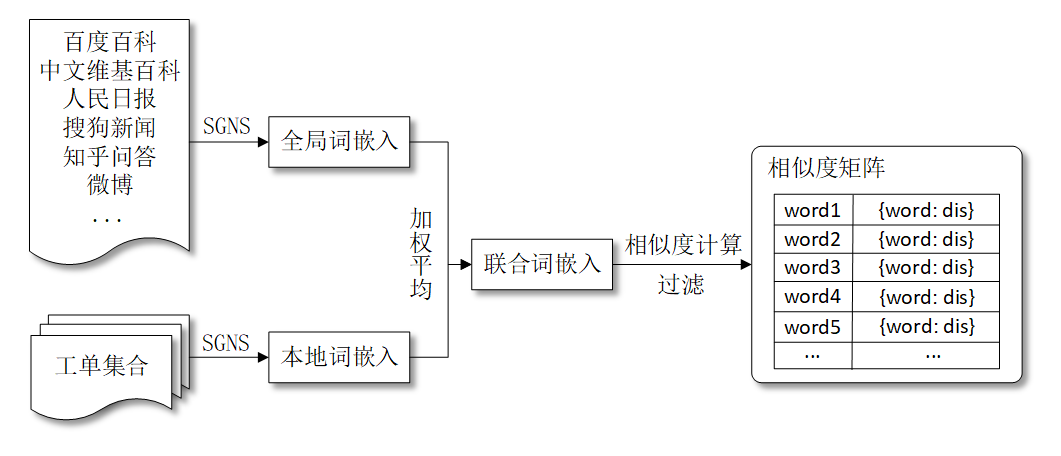
相关研究表明,基于单词共现模式的主题连贯性度量是衡量主题模型质量的可靠指标,因此可以认为,具有高度语义相关性的词语应该出现在同一个主题下。基于这个假设,TSSE-DMM利用广义波利亚罐(Generalized Polya’s Urn,GPU)模型进行语义增强,具体实现方式是:在TSSE-DMM的每轮采样过程中,对主题z下的单词w,增加w在z中出现的概率的同时,增加与w语义相关的单词在z中出现的概率,以提升相同主题下语义相关的单词共现的概率。并且,只对与主题相关的关键词进行语义增强。这样做的好处是在提升相同主题下语义相关单词共现概率的同时,降低噪声单词的引入。为了获取语义相关的单词,需要计算单词间的语义相似度。TSSE-DMM中单词间的语义相似度是通过“联合词嵌入”的余弦相似度来衡量。联合词嵌入是外部词嵌入和本地词嵌入的加权平均,所谓外部词嵌入是指从大型外部语料中获取的词嵌入,本地词嵌入是基于当前语料集训练的词嵌入。假设单词w的外部词嵌入表示为g(w),内部词嵌入表示为l(w),γ代表外部词嵌入所占的比重,则单词w的联合词嵌入表示为:
在获得了每个单词的联合词嵌入之后,通过计算向量间的余弦距离来衡量不同单词之间的语义相似度。假设单词w1和w2的联合词嵌入向量分别表示为v1和v2,则两者之间的语义相似度定义如下:
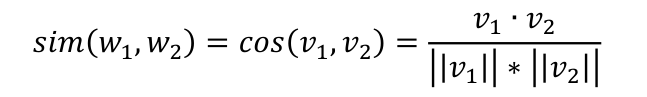
sin(w1,w2)的取值在[0,1]之间,值越大代表单词之间的语义相似度越高。对于训练集中的每个单词w,设定一个阈值τ,假定只有与其相似度分数大于该阈值的单词才被认定为与单词w语义相关的单词,于是可以构造出如下的单词语义相似度矩阵:
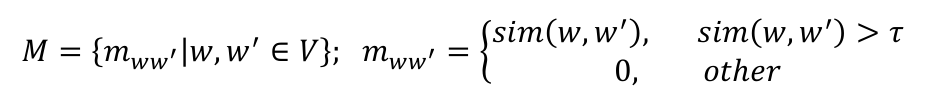
同时,额外引入一个阈值χ,如果与单词w语义相关的单词的数量大于χ,则将M中w所在行和列的值全部置为0。语义增强的整体流程如下图所示:
3.3 使用Collapsed吉布斯采样进行模型推断
在TSSE-DMM中,需要被估计的隐变量是每篇文档的主题z、全局主题分布θ、每个主题对应的单词分布φk,q以及全局背景单词分布η。在Collapsed 吉布斯采样算法的执行过程中,首先为每篇文档随机初始化一个主题,然后通过计算条件概率分布p=(zd=k|z-,d,d,α,β,σ)为每篇文档重新采样一个主题,迭代直至模型收敛,计算公式如下:
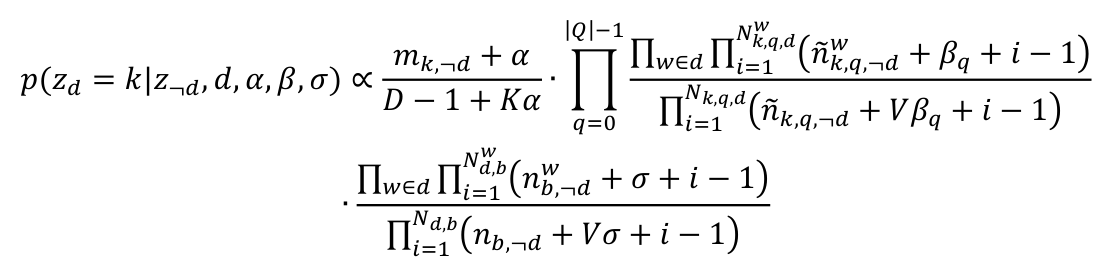
其中,mk代表主题k下的文档数,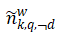 代表在主题k特征q下单词w以及与w语义相关的词出现的次数,
代表在主题k特征q下单词w以及与w语义相关的词出现的次数,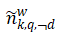 代表主题k下单词出现总数;
代表主题k下单词出现总数;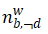 代表单词w采样为背景词的次数;
代表单词w采样为背景词的次数;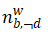 代表被采样为背景词的单词的次数。通过对文档下的主题分布和主题下的单词及语义相关词的主题分布的统计,对全局主题分布θ、每个主题对应的单词分布φk,q、全局背景单词分布η的估计如下:
代表被采样为背景词的单词的次数。通过对文档下的主题分布和主题下的单词及语义相关词的主题分布的统计,对全局主题分布θ、每个主题对应的单词分布φk,q、全局背景单词分布η的估计如下:
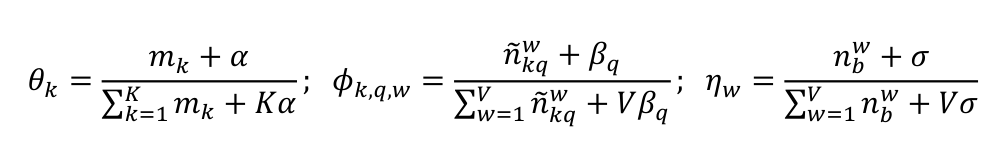
短文本主题模型TSSE-DMM的评估效果
4.1主题质量评价
下表是在中文新闻数据SougouCA(包含3万条不同类型中文新闻数据)上,使用不同短文本主题模型建模,与“神舟九号”相关的主题分布下概率值最高的几个单词,可以发现,相比其他模型,TSSE-DMM能够从主题相关的地点、对象、关键词等方面对主题进行更全面、具体地刻画。同时,模型能够过滤出部分与主题无关的全局背景单词,这些全局背景单词可以作为领域相关的候选停用词加入停用词表中。
4.2 主题连贯性评价
主题连贯性可以用来评估主题模型生成的主题的质量,通过互信息(PMI)来度量。选定个主题,其中的某个主题下概率值最高的前T个单词为(w1,...,wT),主题的PMI值计算公式是:

其中p(wi)代表单词wi在文档中出现的概率,p(wi,wj)代表单词wi和wj共同出现在文档中的概率。模型的主题连贯性则定义为所有主题PMI的平均值,PMI值越高,主题连贯性越高,主题模型的质量就越好。
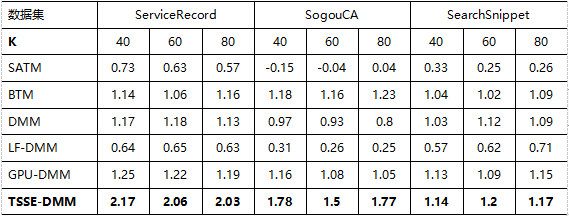
下面的两个表是在SougouCA数据集、SearchSnippet数据集(该数据集是使用8个不同领域的短语在Google搜索引擎进行检索的结果,包含12340条英文短文本数据)和真实世界数据集ServiceRecord(包含江苏公共服务热线的19411条居民投诉建议短文本数据)三个数据集上,选取不同的主题数T={10, 20}和主题下的词数K={40, 60, 80},不同短文本主题模型的主题连贯性的对比。
选取T=10时:
选取T=20时:

可以看出,TSSE-DMM在所有参数设置上的主题连贯性都要优于其它模型。且T的取值越小,主题连贯性越高。
4.3 短文本分类评价
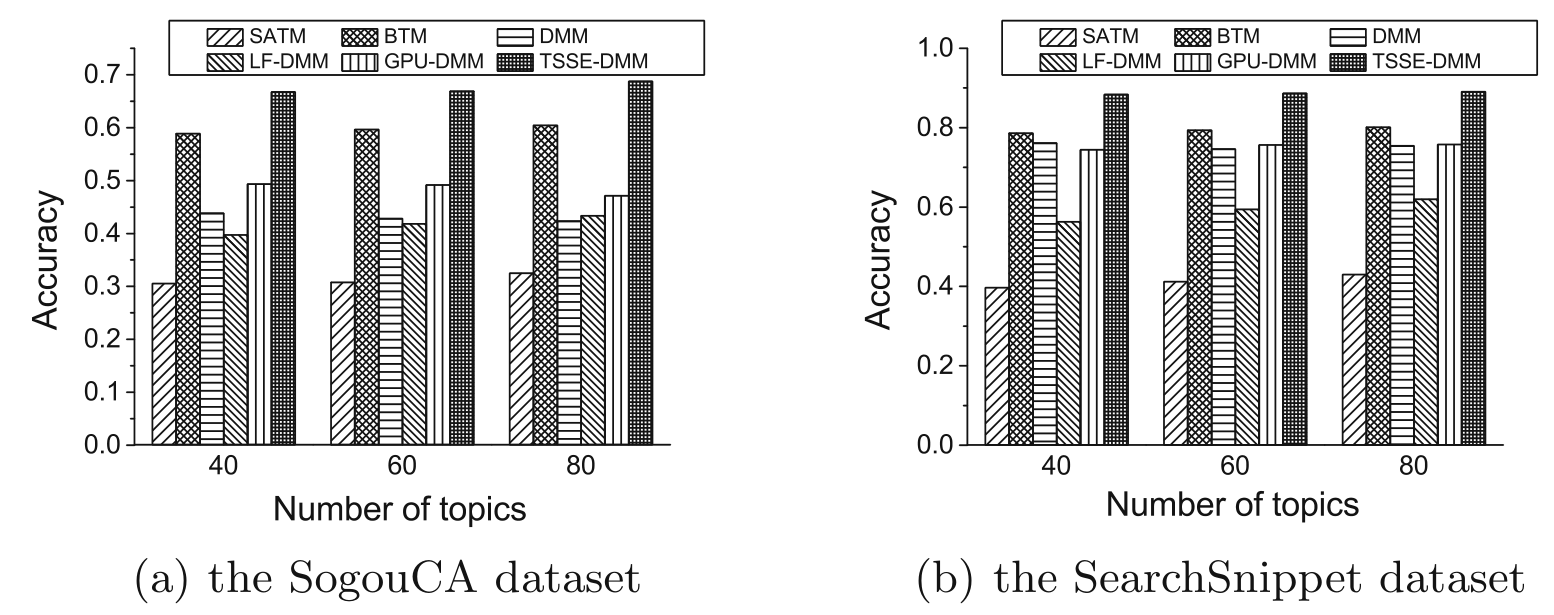
评估主题模型质量的另外一种有效方法是将学习到的主题应用于外部任务,如文本分类和聚类,通过短文本分类任务可以间接评估主题模型的质量。在训练好主题模型后,将每篇文档表示为该文档对应的“文档-主题”分布向量,然后训练一个分类器进行评估。下图是使用支持向量机作为分类器,以分类正确率(Accuracy)作为评估指标,主题数分别设置为,在SogouCA数据集和SearchSnippets数据集上对比不同短文本主题模型的分类效果:
4.4 短文本聚类评价
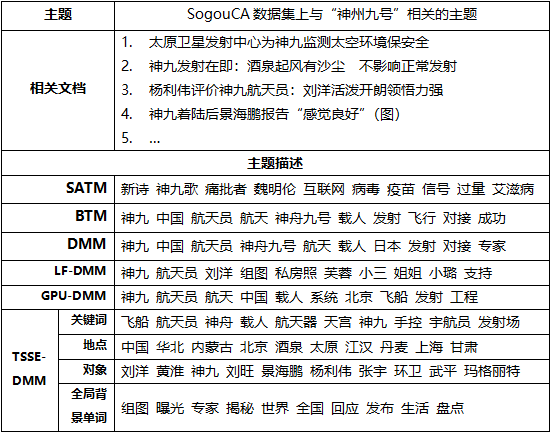
使用短文本聚类分类任务同样可以间接评估主题模型的质量。如果每个主题对应一个类别标签,则将每篇文档分配给其概率最高的主题,从而形成不同的聚类簇。下图分别显示了不同短文本主题模型在SogouCA数据集和SearchSnippet数据集上的聚类结果,使用纯度(Purity)和规范化互信息(NMI)作为聚类评价指标。
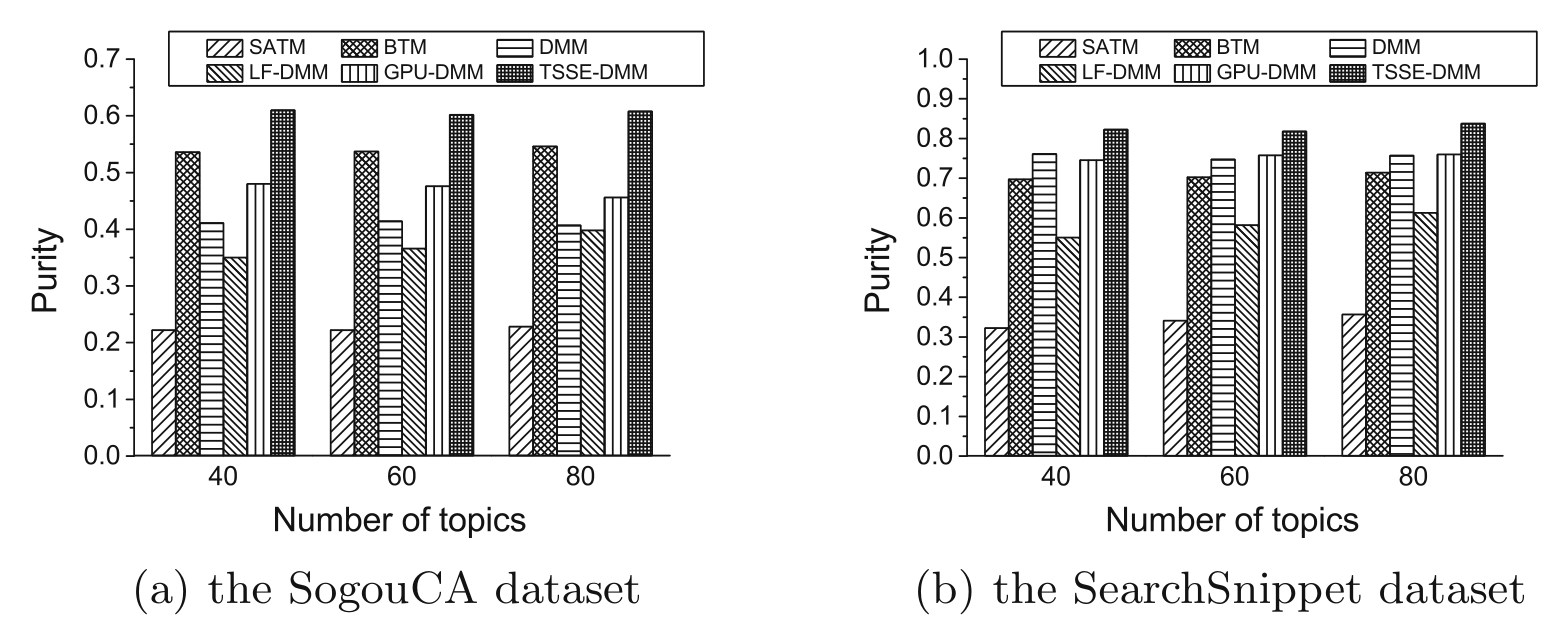
使用NMI作为评价指标:
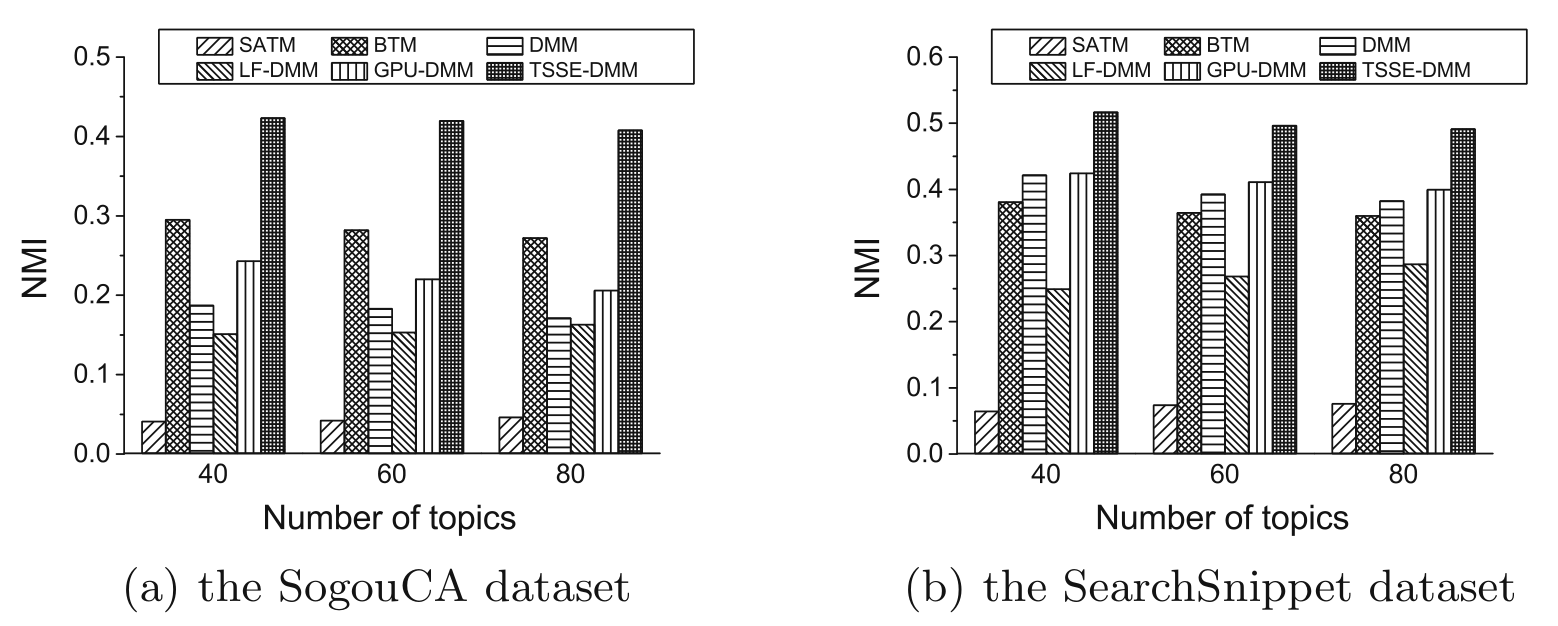
可以看出,TSSE-DMM在聚类任务的两个评价指标上都表现出了最佳性能。
总结
本文介绍了一种新的短文本主题模型TSSE-DMM,模型通过将主题细分为地点、对象、关键词及背景词四方面提高了主题的连贯性和可解释性,并通过语义增强策略缓解文本稀疏性问题。最后,在三个文本数据集上进行的实验结果表明,TSSE-DMM相比其他短文本主题模型,可以实现了更好的主题表示。
参考文献
[1] Mai, Chengcheng, Xueming Qiu, Kaiwen Luo, Min Chen, Bo Zhao, and Yihua Huang. “TSSE-DMM: Topic Modeling for Short Texts Based on Topic Subdivision and Semantic Enhancement.” In Advances in Knowledge Discovery and Data Mining: 25th Pacific-Asia Conference, PAKDD 2021, Virtual Event, May 11–14, 2021, Proceedings, Part II, 640–51. Berlin, Heidelberg: Springer-Verlag, 2021.[2] Blei, David M., Andrew Y. Ng, and Michael I. Jordan. “Latent Dirichlet Allocation.” The Journal of Machine Learning Research 3, no. null (March 1, 2003): 993–1022.
[3] Yin, Jianhua, and Jianyong Wang. “A Dirichlet Multinomial Mixture Model-Based Approach for Short Text Clustering.” In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 233–42. KDD ’14. New York, NY, USA: Association for Computing Machinery, 2014.