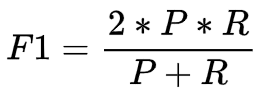作者:鲍春晓
前言
本文对赛题《高鲁棒性要求下的领域事件检测任务》的比赛经历进行了分享。首先分析了赛题的难点,然后提出了一套有效的算法方案,该方案取得了复赛14名的好成绩,最后对比赛过程中的不足进行了反思。
赛题说明
《高鲁棒性要求下的领域事件检测任务》是2022全国大数据与计算智能挑战赛的赛题之一。该赛题提供标签污染的军事新闻数据,要求选手设计高鲁棒性的事件检测算法,对测试集的触发词和事件类型进行预测。
1.1 数据说明
赛题提供了训练集7000条,验证集1500条,初赛测试集2000条,复赛测试集3500条。数据格式示例如下(编造的示例数据,非比赛数据):

图1-1 数据示例
event_mention为事件信息,其中trigger和event_type为赛题要求预测的触发词和事件类型,arguments为事件的论元信息,trigger中的offset则指明trigger由tokens中的哪些token组成。entity_mention和relation_mention分别是实体信息和关系信息,为额外可利用的标注信息。
1.2 标注类型说明
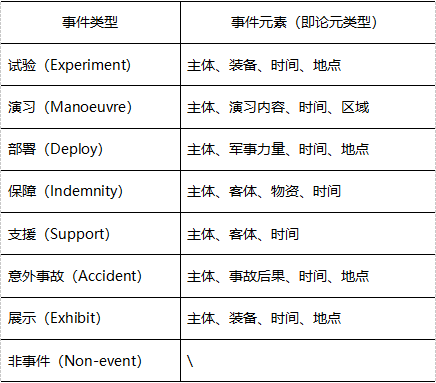
标注的事件类型有8种,实体类型有7种,关系类型有8种。
表1-2 实体和关系类型说明

1.3 标签污染
赛题明确指出,训练集和验证集存在一定程度的标签污染。具体存在哪些污染,赛题主办方只指出事件类型存在错误,至于其他标签,如触发词的offset,实体类型、关系类型等,是否存在错误,以及标签污染的程度,赛题主办方就没有告知了。
1.4 评分指标
赛题采用Macro F1值进行评分,即:7种事件类型(不包括非事件)F1值的平均值。P(准确率) = 预测正确的数据个数 / 预测为k的数据个数R(召回率) = 预测正确的数据个数 / 标注为k的数据个数
其中,预测正确的评判标准为"event_type"字段、"trigger"字段以及"offset"字段,预测的结果与标注的结果完全一致。
赛题分析
从赛题名称和示例数据不难发现,赛题有以下难点:(1)标签存在污染(2)预测任务复杂(3)触发词、实体、关系的标注格式不同
2.1 标题存在污染
所谓“数据决定上限,模型决定下限”,数据的标签存在污染是个必须要解决的问题。虽然也有一些比较稳健的模型(如随机森林),但是归根究底,数据的质量还是第一位的。所以如何解决标签的污染,就是首先要考虑的。目前明确已知的,就是事件类型存在污染。人工观察了几十条数据,发现事件类型的错误确实蛮严重的(主观感受约有30%的数据,事件类型被标错了)。但是事件类型虽然标错了,论元类型标注质量挺高的,几乎没有错误。同时观察表1-1,发现有部分事件存在典型论元,如演习内容、军事力量,这些论元只会在对应的事件类型中出现。于是考虑,是否可以依据数据的论元类型纠正事件类型?
2.2 预测任务复杂
(1)数据有没有事件,即数据的事件类型是不是非事件(Non-event)(2)若数据有事件,数据的触发词是哪个,即预测触发词的offset
针对(1),通过统计,发现在8500条全量数据(训练集+验证集)中有3976条为非事件,占比46.7%,接近一半。如果认为数据存在事件,那么既要预测trigger又要预测事件类型,还是比较困难的。但是如果认为数据不存在事件,那么本质上就是个二分类预测(有/没有事件),预测难度将低很多。实际上确实存在大量的非事件(接近一半),因此可以预期,将非事件预测得准是提高分数(提高模型精度)的简单又有效的方法。
针对(2),这其实涉及到如何建模的问题。比较容易想到的方案就是将触发词看成实体,将触发词的offset预测看成实体识别任务,这里又细分为两种做法:序列标注、span分类。序列标注即给数据打上一个标注序列,然后训练模型去预测标注序列。标注的方法有BIO、BIOES等,这里不做赘述。span分类是依据数据的文本生成若干个span(一小段连续子文本),然后对这些span进行分类。通过统计,发现在全量数据中,有97.9%的trigger只由1个token组成。因此,若采用span分类法,可以将问题简化为对token的分类问题。
针对(3),其实可以将触发词预测和事件类型预测看成两个独立的任务,也可以看成相关的任务。若看成独立的任务,那事件类型预测就是一个文本分类任务。若看成相关的任务,则在序列标注法中,将事件类型看成标注序列中的一类实体即可;在span分类法中,将事件类型直接作为span的类别即可。
2.3 触发词、实体、关系的标注格式不同
触发词是必须要利用的信息,实体标注和关系标注是额外的信息。观察图1-1可以发现,触发词、实体、关系的标注格式是不同的。若想利用实体关系这两类额外信息,就需要解决“怎么用”的问题。
算法设计
3.1 事件类型纠正
3.1.1 论元类型纠正事件类型
通过Arguments标注可知数据的论元类型有哪些,通过表1-1可知每个事件类型对应的标准论元类型。设数据为D,数据的论元类型为S,事件的标准论元类型为Ŝ,那么算法的流程如下:

3.1.2 触发词文本纠正事件类型
经过1,统计每一个触发词文本在每一个事件类型下的比例,设该比例为R。以”坠毁. Accident.R = 0.2”举例说明,意思是:事件类型为“Accident”的数据中,触发词为“坠毁”的数据占比20%。若某触发词在某事件类型下未出现过,则令R等于0。算法的流程如下:
3.1.3 纠正统计
经过“论元类型纠正事件类型”,在4524条有事件标注的数据中,纠正了数据612条,标记为next的数据215条。
经过“触发词文本纠正事件类型”,在215条标记为next的数据中,纠正了数据200条,仍然有15条未纠正。因数量过少,对这15条仍未纠正数据不再进行处理。
3.2 PURE建模
算法使用的模型为PURE,该模型由论文《A Frustratingly Easy Approach for Entity and Relation Extraction》提出。使用该模型,原因之一是论文被国际顶会NAACL 2021收录,说明模型确实性能优秀;原因之二是该模型的数据组织格式允许将触发词、实体标注、关系标注的格式进行统一,同时还允许将“事件/非事件 二分类预测”、“触发词预测”、“事件类型预测”三种任务形式统一;原因之三是在比赛开始之前,PURE的训练、预测功能已经完成,在时间紧张的赛程中,省去模型训练、模型预测的代码编写过程,可以节约大量的时间。
3.2.1 PURE简介
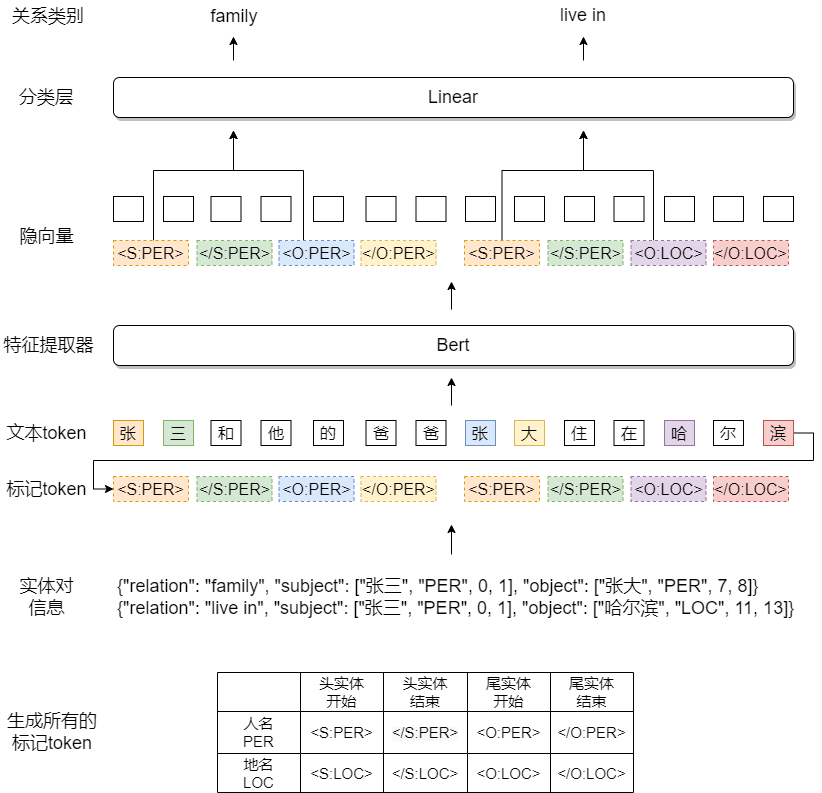
为了说明算法的建模流程,需要对PURE进行一个简要的说明。PURE本质上是解决关系分类的模型,关系分类是这样一种任务:给定一组实体对(头实体,尾实体),预测两个实体的关系类型,头尾实体用(实体类型,offset)表示。具体到PURE,首先为每一个实体类型生成4个标记token,然后给定一组实体对,取出该实体对对应的4个标记token,接着顺序拼接所有实体对的标记token到文本token后面,之后将token传给特征提取器(一般为Bert),拿到每个token的隐向量输出,最后每4个标记token选择第1个和第3个标记token的隐向量进行拼接,传给分类层进行分类即可。
PURE所需要的输入实体对格式如图3-1的实体对信息所示。也就是说,尽管触发词、实体、关系的标注格式都不同,但只要运用点技巧,将格式统一成图3-1的实体对信息即可。算法最终使用字符级别的文本token,并将offset也进行了相应的转换。模型的输入数据格式如下图所示:
在文本token前添加一个固定的特殊token“[CLS]”,然后生成CLS 实体对。实体类型为固定的CLS,offset为固定的[0,0],关系类型为Event或Non-event。该实体对负责预测数据有没有事件。
依据赛题给出的触发词标注信息生成该实体对。实体类型为固定的Trigger,关系类型为七种事件类型(除了Non-event)之一。该实体对负责预测事件类型。依据赛题数据tokens字段中的每一个token(即赛题给出的分词结果中的每一个词)生成采样 实体对。实体类型为固定的Trigger,关系类型为固定的Non-Trigger。在训练时,该实体对负责将非触发词的token预测为Non-Trigger;在预测时,该实体对负责在”七种事件类型+Non-Trigger”中进行预测。
依据赛题给出的实体标注信息生成该实体对。实体类型即为赛题给出的实体类型,关系类型为固定的Entity。该实体对不负责预测,目的是提供辅助信息。
依据赛题给出的关系标注信息生成该实体对。实体类型为赛题给出的关系类型,关系类型为固定的Relation。该实体对不负责预测,目的是提供辅助信息。
3.3 结果提交算法
PURE训练完成之后,就可以对测试集每一条数据的实体对进行预测。一条数据的最终提交结果算法如下:

成绩与反思
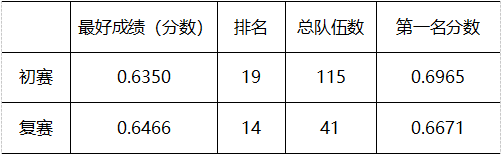
在两个星期的赛程之后,该套算法的最终线上分数及排名如下:
赛后回顾的话,其实也有不少值得反思的地方,比如下面两点:
实际上在比赛过程中,总是会有很多的idea出现,但是如何评估这些idea是否真的有效果?赛题一天只有宝贵的3次提交机会,靠线上提交来评估idea肯定不现实。赛后反思的话,感觉一套能够有效评估idea有效性的指标方法还是很重要的。一是可以节约线上提交的机会,二是当idea尝试到一半时若发现效果并不好,可以及时中止,避免再投入时间。
当线上成绩迟迟无法提升时,对模型做下错因分析,也许就能发现一些有效的思路。比如下面这条文本(编造的示例文本,非比赛文本):“舒克和贝塔用从罗丘那里拿到的新飞机、新坦克持续性地进行演练。鼠王看到这些新亮相的玩具,吓得躲进老鼠国,再也不敢出来了。”模型在事件预测时对这条文本中的“演练”和“亮相”都给出了较高的概率。这也很好理解,因为演练是事件Manoeuvre下的高频触发词,而亮相是事件Exhibit下的高频触发词。实际上,这条文本的事件类型是Manoeuvre。这提示也许模型预测错误的重要原因之一就是文本中出现了多个可以作为触发词的token。
为了解决这个问题,也许可以先抽取出文本的中心语义(类似文本摘要)。比如上面的文本,如果能够抽取出“舒克和贝塔用从罗丘那里拿到的新飞机、新坦克持续性地进行演练。”这一中心语句,然后在中心语句上做赛题的任务,就能规避其他高频触发词的影响,也许效果会好一些。可惜的是,当赛程后期发现这个问题和思路时,已经没有时间尝试了。
总结
本文按照“赛题说明-赛题分析-算法设计-成绩与反思”的流程详细论述了《高鲁棒性要求下的领域事件检测任务》赛题的任务难点、心路历程、反思不足。这一流程对任何算法建模任务都具有参考价值。另外,本文所设计的算法方案,并不仅仅只能用于该赛题,也可以适用于事件抽取、关系分类、实体识别等相关任务。