作者:于辉、麦丞程、骆楷文(南京大学PASA大数据实验室)
自然语言处理数据标注
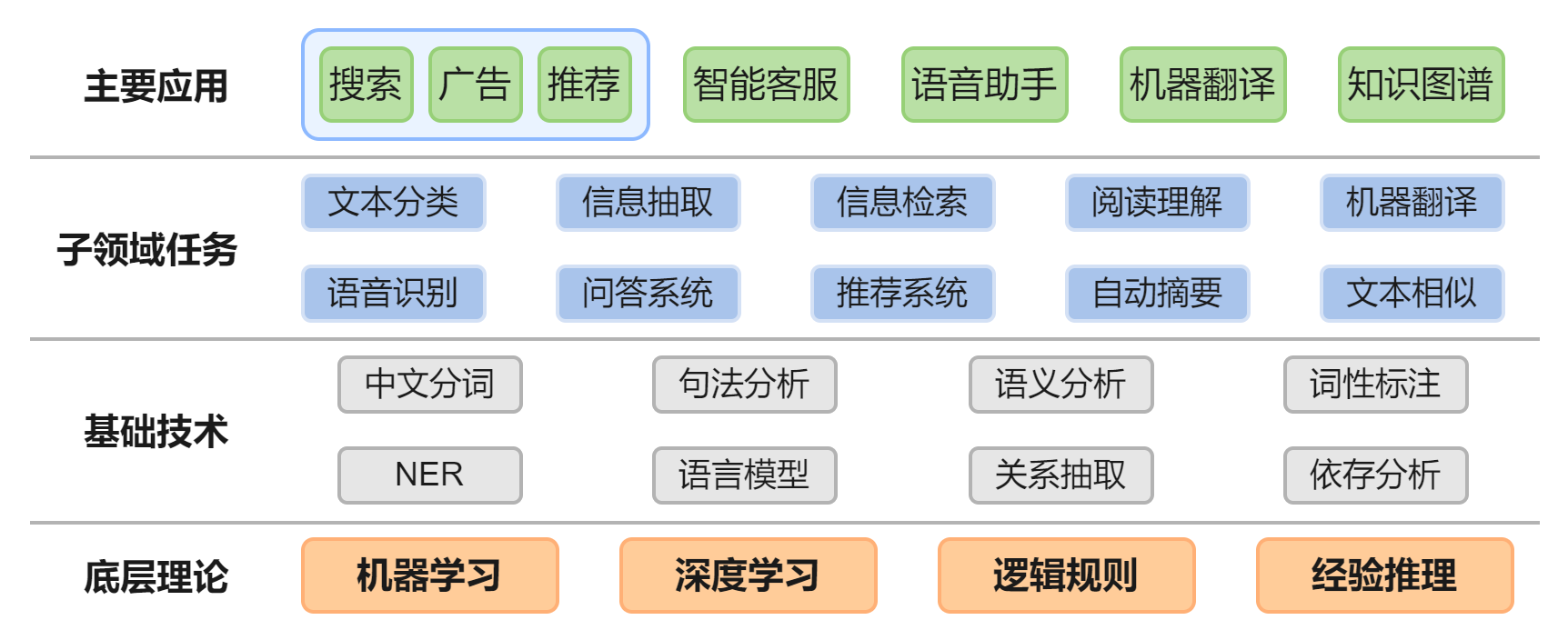
自然语言处理(NLP)是语言学、计算机科学和人工智能的交叉学科,主要研究计算机和人类语言之间的交互,尤其是如何编程实现让计算机处理和分析自然语言。自然语言处理有如下图所示的常见应用和一些主要子领域任务:
图1 NLP主要技术
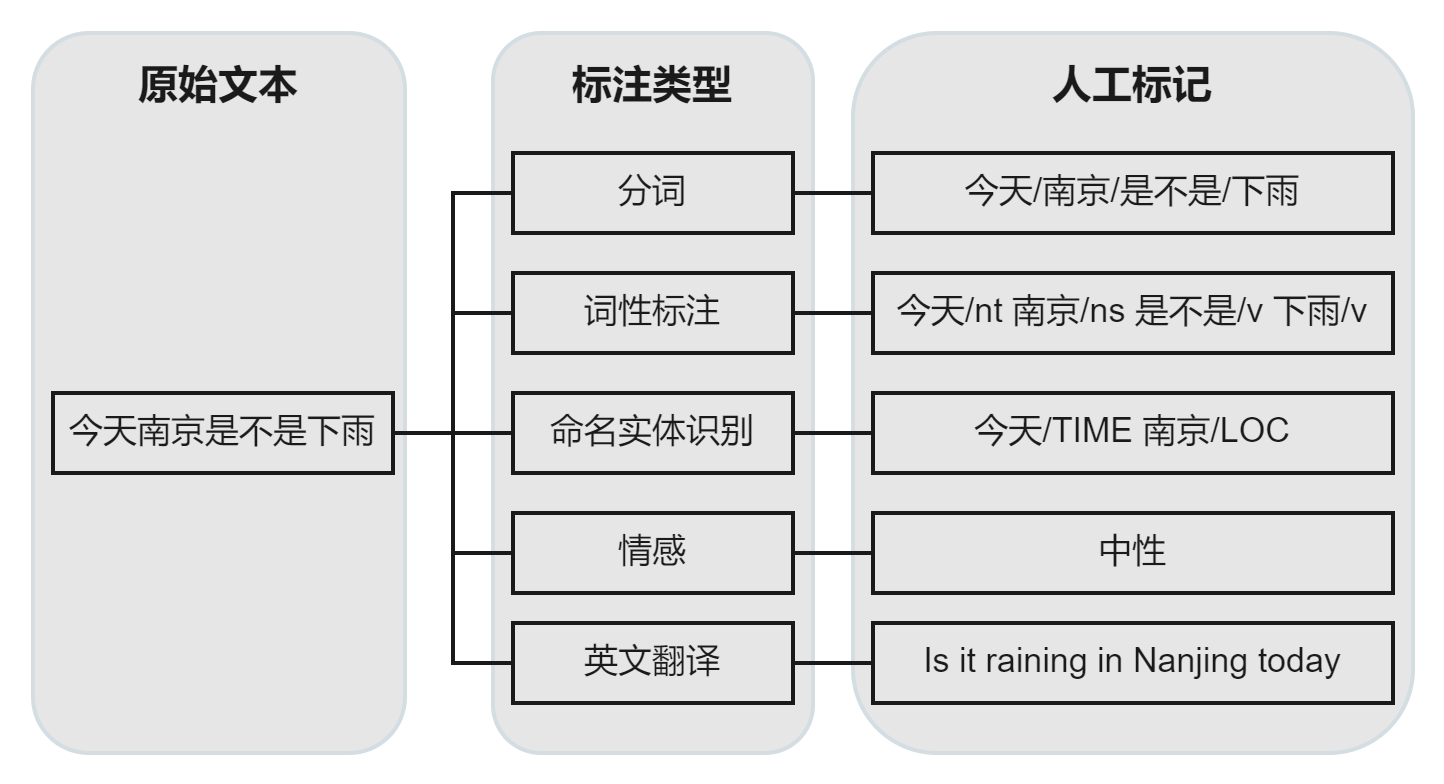
如今,基于深度学习的方法已经在各个NLP子领域任务中成为主流,在学习阶段,深度学习模型都需要特定格式的输入文本,例如,文本分类任务需要输入 (文本, 分类标签) 数据,机器翻译任务需要输入 (原始文本, 译文) 数据,等等。生成这些“特定格式的输入文本”的过程,就是文本标注。同时,针对不同类型的NLP任务,文本标注分为类别属性标注、实体及关系标注、情感标注等等不同类型,下图展示了一些常见的文本标注类型
图2 文本标注常见任务
只有获得标注好的文本数据后,各种基于机器学习、深度学习的方法才有用武之地,才可以“教会”机器识别文本中隐含的意图或情感,使机器可以人性化地理解自然语言。所以说,没有文本标注,自然语言理解就无从谈起。
文本标注中的挑战
在大数据与高性能算力的助力下,深度学习掀起了一波浪潮,在许多领域取得了显著的成绩。以监督学习为主的深度学习方法,往往期望能够拥有大量的标注样本进行训练,这样模型才能够学到更多有价值的知识。例如,机器阅读理解领域的标准数据集SQuAD(斯坦福问答数据集),其中包含10万多个问题与答案对,这些问题与答案对都是由人工创建及回答的,并经过人工校验。然而,实际应用场景的标注样本严重稀缺,且标注大量样本将产生昂贵的标注成本。SQuAD数据集是斯坦福大学研究员从维基百科中筛选出500多篇文章后,又花费数周时间,以9美元每小时的时薪招募多组众包人员进行标注的,每个问题答案对中的问题与答案都是由不同标注员生成及回答的。综上,在各种实际应用场景,对高质量标注数据的需求比比皆是。因此,如何“在模型达到目标性能的前提下,尽可能地减少标注成本”是一项亟需解决的挑战。主动学习作为机器学习的一个子领域,旨在以尽可能少的标注样本达到模型的目标性能,为降低文本标注成本提供了新方法。
半自动数据标注方法:主动学习
3.1 主动学习简介
主动学习是一种通过主动选择最有价值的样本进行标注的机器学习或人工智能方法。其目的是使用尽可能少的、高质量的样本标注使模型达到尽可能好的性能。也就是说,主动学习方法能够提高样本及标注的增益,在有限标注预算的前提下,最大化模型的性能,是一种从样本的角度,提高数据效率的方案,因而被应用在标注成本高、标注难度大等任务中,例如医疗图像、无人驾驶、异常检测、基于互联网大数据的相关问题。
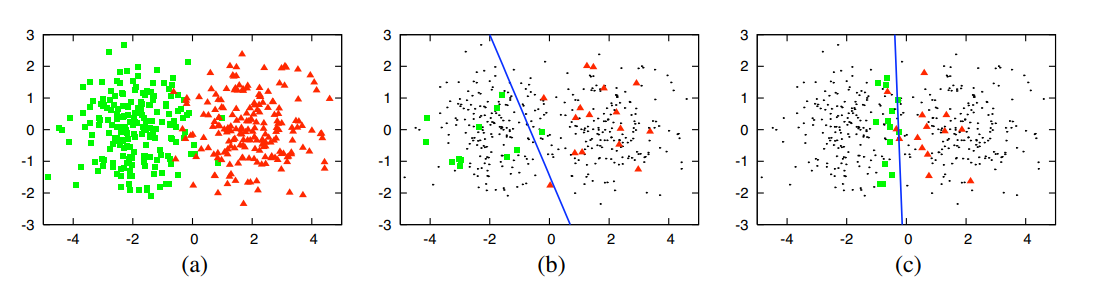
《Active Learning Literature Survey》中首次系统性地阐述了主动学习相关工作,以一个2D空间数据点二分类任务的简单实验说明主动学习作用:
图 3 主动学习实验
图3 (a) 表示样本量为400的二分类数据集。图3 (c) 中使用主动学习策略选取30个样本作为训练集训练出的逻辑回归模型可达到90% 的准确率,而图 (b) 中随机选取30个样本训练出的模型只达到70%的准确率。
由此说明,样本对模型的贡献并不是一样的,选择更有价值的样本具有实际意义。当然,如何确定和评估样本的价值也是主动学习研究的一个重点。
3.2 主动学习流程
(1) 主动学习方法介绍
在学术界,同样有学者在关注这方面的问题,研究者通过一些技术手段或者数学方法来降低人们标注的成本,学者们把这个方向称之为主动学习(Active Learning)。在整个机器学习建模的过程中有人工参与的部分和环节,并且通过机器学习方法筛选出合适的候选集给人工标注的过程。
主动学习的大致思路就是:通过机器学习的方法获取到那些比较“难”分类的样本数据,让人工再次确认和审核,然后将人工标注得到的数据再次使用有监督学习模型或者半监督学习模型进行训练,逐步提升模型的效果,将人工经验融入机器学习的模型中。
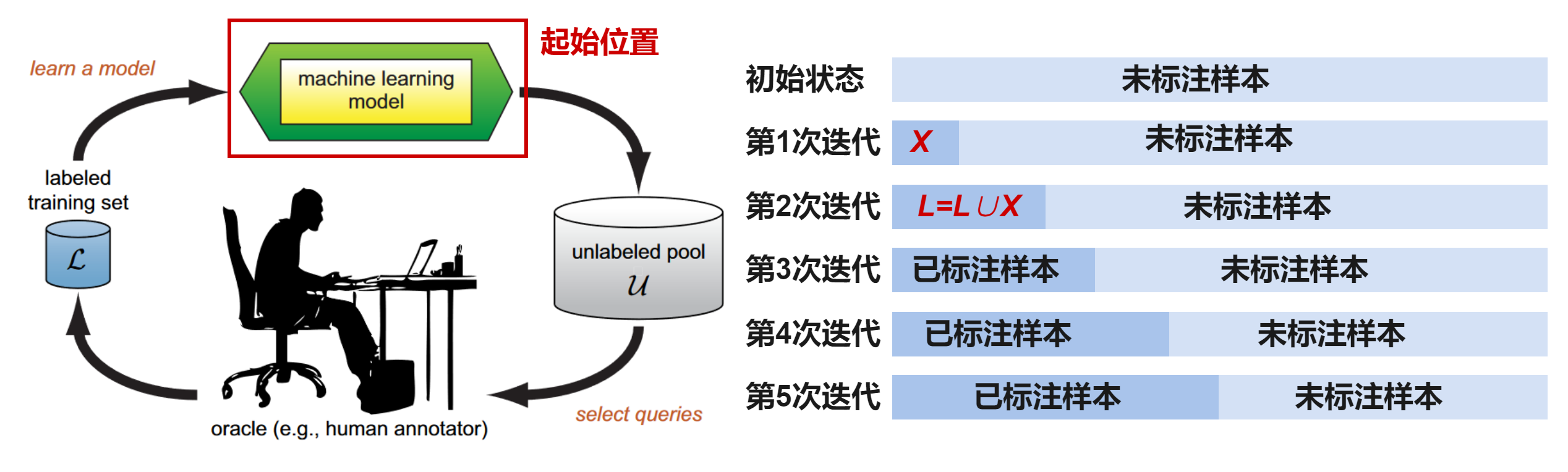
主动学习方法是一个迭代式的交互训练过程,主要由五个核心部分组成,包括:未标注样本池(unlabeled pool, U)、查询策略(select queries, Q)、标注者(human annotator, S),标注数据集(labeled training set, L),目标模型(machine learning model,G)。主动学习将上述五个部分组合到同一个流程中,并通过如下图所示的顺序:
1)在已经标注的少量数据上训练出基于小样本的模型;
2)使用训练出的小样本模型,从未标注样本池中进行筛选出高质量的未标注样本;
3)将筛选出的高质量未标注样本推荐给领域专家进行人工标注,并且标注后的数据用于模型更新训练;
4)不断迭代地进行上面三个步骤,直到目标模型准确性满足实际需求或者无标注样本集合为空集。
图 4 pool-based主动学习流程
以上描述的是经典的 pool-based 模式主动学习方法。由于其与深度学习中的 “mini-batch learning”的训练方法契合,更容易加入到已有工作流中。在每次的主动学习循环中,根据任务模型和无标签数据的信息,查询策略选择最有价值的样本交给专家进行标注并将其加入到有标签数据集中继续对任务模型进行训练。
(2) 主动学习查询策略
如何确定和评估样本的价值是主动学习研究的一个重点,即如何设计一个查询策略来判断样本的价值,即是否值得被人类专家标注。考虑到样本的价值并不是一成不变的,它不仅与样本自身有关,还和任务和模型等因素有关。回到图3的二分类问题,使用了主动学习策略的(c)说明更接近分类边界的数据点,对分类模型的训练更有价值,因为它更难分类,而其他远离分类边界的数据点,相对而言重要性就不那么高了,因为模型想要对它分类并不难。因此,查询策略的设计并不是简单和一成不变的,需要根据具体环境、问题和需要进行设定。这样就产生了各种各样的查询策略:
1.随机采样 (Random Sampling,RS): RS 不需要跟模型的预测结果做任何交互,直接通过随机数从未标注样本池筛选出一批样本给专家标注,常作为主动学习算法中最基础的对比实验。
2.不确定性采样(Uncertainty Sampling,US): 主动学习中最简单直接也是最常用的策略。US 假设最靠近分类超平面的样本相对分类器具有较丰富的信息量,根据当前模型对样本的预测值筛选出最不确定的样本。为了衡量“不确定性”,US 包含了一些基础的衡量指标:如最小置信度(Least Confidence,LC)、边缘采样(Margin Sampling,MS)、多类别不确定采样(Multi-Class Level Uncertainty,MCLU)、熵值最大化(Maximize Entropy,ME)、样本最优次优类别(Best vs Second Best, BvSB)等。
3.多样性采样 (Diversity Sampling) :是从数据的分布考虑的常用策略。算法根据数据分布确保查询的样本能够覆盖整个数据分布以保证标注数据的多样性。例如,老师在出考试题的时候,会尽可能得出一些有代表性的题,同时尽可能保证每个章节都覆盖到,这样才能保证题目的多样性全面地考察学生的综合水平。在多样性采用的方法中,有基于模型的离群值、代表性采样、真实场景多样性、预期模型改变(Expected Model Change)、委员会查询 (Query-By-Committee)等等。
此外,有些研究者将多种查询策略结合起来使用混合策略进行查询,例如即考虑不确定性又考虑多样性的。还有一些其他的查询策略,例如预期误差减少、方差减少、密度加权法等。
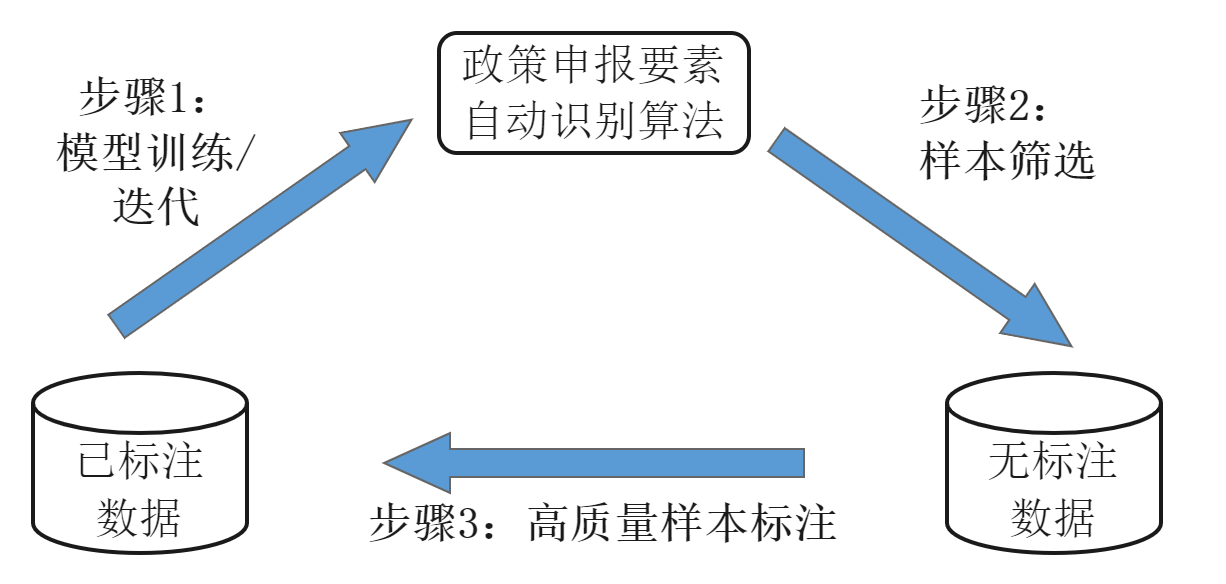
实例:主动学习应用于政策申报要素自动抽取
政府发布的各类奖补政策在行业发展中有重要导向作用,研究使用人工智能的方法实现政策申报要素自动抽取对企业来说具有很高的实用价值。实现政策要素自动抽取,首先是要对政策文本申报条件语句中包含的申报要素(如企业资质、注册地址、从业人数等等)进行标注。但是,面向政策文本的标注数据十分稀缺,并且,标注难度也更大。因此,如何实现在需要标注尽可能少的数据的情况下,使得算法模型取得尽可能高的准确性,节省数据标注的成本,成为一个需要亟需解决的问题。为此,我们引入了了主动学习的方法:首先,在已经标注的少量数据上训练出小样本政策申报要素自动识别模型;然后,使用训练出的小样本政策申报要素自动识别模型对未标注样本进行筛选,得到高质量的未标注样本;接着,对筛选出的高质量未标注样本推荐给领域专家进行人工标注,并且标注后的数据用于模型更新训练;最后,不断迭代地进行上面三个步骤,直到政策申报要素自动识别模型准确性满足实际需求或者无标注样本集合为空集。
4.1实验设置
在人工收集整理的包含3210条标注样本句子的政策数据集上,我们实验了基于最小置信度(LC)、最大标准化对数概率(MNLP)、贝叶斯非一致性(BALD)三种不确定性采样方法,以验证主动学习方法的有效性,并和随机样本采样方法(Rand)进行了对比。置信度指模型Mt从样本句子 x 中预测出政策申报要素实体集合 S 的概率,具体计算公式如下:
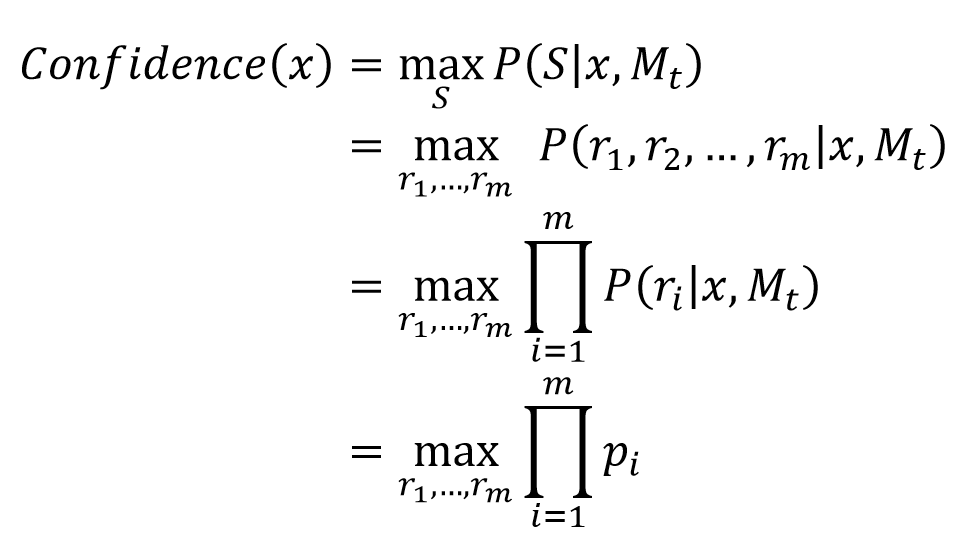
即模型Mt预测样本句子政策申报要素三元组集合 S 中的i个关系三元组ri的概率pi的乘积为置信度。基于最小置信度的不确定性采样方法目的是采样置信度小的样本作为高质量样本。所以,未标注样本句子x的不确定性分数计算公式如下:
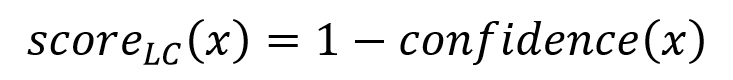
其中,confidence(x)表示未标注样本句子x的置信度;scoreLC(x)表示未标注样本句子的不确定性分数。在计算出所有未标注样本的不确定性分数之后,将所有未标注样本按其不确定性分数从大到小进行排序,选取不确定性分数最大的前K个未标注样本,进行人工标注。最大标准化对数概率是对最小置信度方法里的置信度取对数:
同样,选取不确定性分数最大的前K个未标注样本提交人工标注。最大标准化对数概率的方法可以避免置信度优先方法倾向于选择包含更多政策申报要素三元组的样本的问题。
与前两种方法不同,贝叶斯非一致性方法对未标注的样本句子进行多次预测,并在每次预测时使用蒙特卡罗dropout方法,使每次结果都不完全相同,避免单次预测的偶然性,提升预测结果的泛化性。基于该方法,未标注的样本句子x的不确定性分数计算公式如下:
使用蒙特卡罗dropout对未标注样本句子x的政策申报要素实体进行T次预测,预测结果为T个三元组集合Si~ST,Sall表示Si~ST的并集。Si(r)表示判断政策申报要素三元组集合Si中是否包含关系三元组r的函数,如果Si包含r则输出结果为1,否则输出结果为0。
计算Sall中每个关系三元组r出现在T次预测结果中的次数和,除以所有关系三元组的个数与预测次数的乘积,得到模型Mt进行T次预测出的结果不一致性;最后,计算出未标注样本对应的不确定性分数scoreBALD(x),选取不确定性分数最大的前K个未标注样本提交人工标注。
4.2实验结果
图 6 不同采样方法下基于主动学习的政策要素抽取实验结果上图是三种不确定性采样方法和随机样本采样方法的实验结果。实验结果表明:1)三种样本不确定性采样方法 LC、MNLP与 BALD 筛选出的高质量样本训练出的模型,在政策申报要素实体抽取任务上的 F1 指标都高于随机采样算法 Rand。证明了主动学习方法能够在有效提升政策申报要素自动识别模型训练的准确性。2)当样本比例在 10% 到 50% 时,本章原型系统中三种样本不确定性采样算法 LC、MNLP 与 BALD 筛选出的高质量样本训练出模型的准确性逐步提升;当样本比例进一步提高,三种样本不确定性采样算法筛选出的高质量样本训练出模型的准确性开始稳定。该现象说明主动学习方法能够筛选出未标注数据中的高质量样本,经过专家标注后用于模型训练迭代,仅需要标注 50% 的数据即可达到 100% 数据量的准确性,从而节省50%的标注成本与时间。
总结
本文概述了文本标注对自然语言理解的重要性,以及文本标注中遇到的问题,然后着重介绍了一种降低文本标注成本的方法,主动学习的概念和流程;最后在政策申报要素自动识别数据标注和模型训练的实验中,发现使用主动学习方法,可以节约一半的文本标注时间和人力成本。验证了主动学习可实现以较少的标注样本达到模型的目标性能,为降低文本标注成本提供了新方法。
参考文献
Settles, Burr. 《Active Learning Literature Survey》. Technical Report. University of Wisconsin-Madison Department of Computer Sciences, 2009. https://minds.wisconsin.edu/handle/1793/60660.
推荐阅读
宝藏神器!5分钟自测高企评审分值!