

2022-06-02
分享到前言
典型的机器学习应用主要包含数据收集、模型构建以及模型预测三个步骤。其中,模型构建是机器学习应用的关键。然而,模型构建存在着技术门槛高、大量依赖专家经验、费事费力等痛点。近年来,利用机器替代人工专家建模的自动化机器学习技术得到了越来越多的关注,并且成为了学术界和工业界的研究热点。已有的自动化机器学习技术主要针对静态数据集,实现自动化建模。也就是说,在建模过程中,数据的分布是固定的。然而,在现实许多应用场景中,如推荐系统、在线广告、欺诈检测、情感分析等,数据集往往是持续产生的。例如,数据是一批一批按天、周、月、年依次到来,数据的分布也可能会随着时间的推移发生变化,导致采用历史数据训练出的模型在新数据上预测精度下降,给自动化机械学习建模提出了更高的要求。
本文所述AutoLLE技术内容,参加了NIPS 2018举办的第三届AutoML国际大赛,在全球348支参赛队伍中,我们PASA实验室团队取得国际第三名的优异成绩。
研究背景
数据分布随时间连续变化场景下的机器学习也称为终生学习(Lifelong Learning)或者持续学习(Continuous Learning),终生学习强调的是对数据分布变化的适应能力。在机器学习理论中,数据的分布也称之为概念(concept)。以监督学习中的分类任务为例,概念代表了样本空间X到标记空间y的映射关系。令Pt(y|X)为在时刻t下X到y的条件概率分布。给定时刻t0和t1,t0
为此,提出了面向终生学习场景的自动化机器学习解决方案,简称AutoLLE(AutoML for Lifelong Learning based on Weighted Ensemble)。AutoLLE集成了全局增量模型和局部集成模型,并基于时间窗口和误差度量自适应调整各个模型的权重,从而能够高效自动地捕捉概念漂移,并通过自动更新模型,提升模型预测性能。
在终生学习场景中,数据是按照一定周期如天、周、月等一批一批依次到来,并逐渐累积。为模拟现实应用场景,将自动化终生学习问题建模如下:
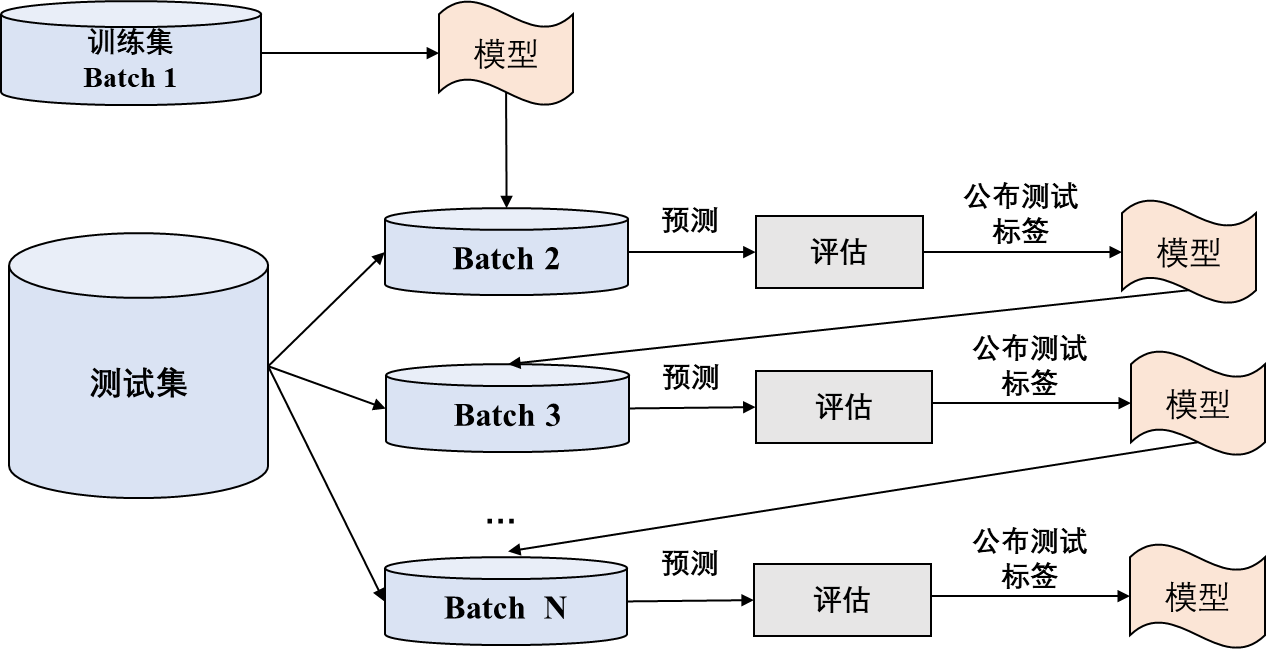
图1 自动化终身学习示意图
将数据集按照时间先后顺序划分为N批,分别为B1,B2...,BN。每一批代表终生学习场景中的一个周期的数据。第一批数据将作为初始的训练集,用于训练初始模型。剩余N-1批数据将作为测试集,用于评估自动化终生学习算法的预测性能。根据第一批数据训练的模型将用来预测第一个测试批(即第二批)的标签。然后,根据指定的评估指标如AUC等,评估并记录在第一个测试批上的预测性能。接着,将公布第一个测试批上的真实标签。自动化终生学习算法将根据第一个测试批的数据和标签自动更新模型,并用来预测后续测试批的标签。当评估完所有的测试批后,整个过程结束。最终,将模型在所有测试批上的平均预测性能作为自动化终生学习算法的评价标准。
值得注意的是,不同批的数据之间是存在时间先后顺序的。随着时间的推移,新的窗口的数据可能存在概念漂移,之前训练的模型可能不再准确。自动化终生学习算法的目的就是能够自动捕捉概念漂移,通过自动更新模型,提升预测性能。
为了能够自动捕获概念漂移,提出基于加权集成学习的算法框架。图2展示了算法框架示意图,首先为了更好地捕获数据集中存在的长期概念,提升模型对长期概念的泛化能力,引入了全局增量模型g,并通过在线学习不断训练全局增量模型。其次,为了及时捕获短期概念,适应概念变化,针对每一批数据引入了局部集成模型H。局部集成模型的训练数据来自于当前批。基于自适应模型加权集成的算法框架如下图所示,下面将对全局增量模型、局部集成模型的构建和自适应权重设计进行介绍。
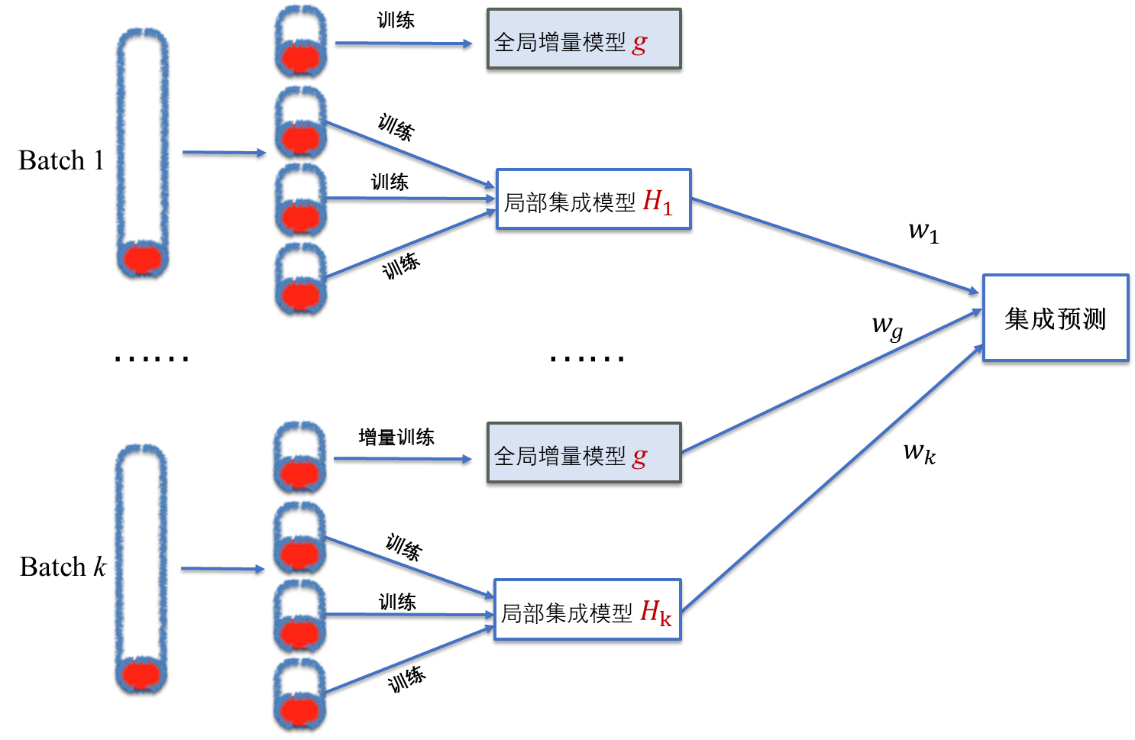
图2 基于自适应模板加权集成的算法框架
在上图所示的整个预测分析过程中,仅维护一个全局增量模型实例,当新一批数据到达后,根据新一批的数据对全局模型进行增量训练,实现全局增量模型的动态更新。因此,可选择支持增量训练的分类器例如Online GBDT等作为全局增量模型。
另外,在大部分实际分析场景中,除了概念漂移,还存在类别不平衡的问题。如上图所示,红色代表了负样本,正负样本比例严重不平衡。因此,为了降低因类别不平衡对全局增量模型造成的性能影响,可对当前批数据进行下采样,利用采样数据而不是全部数据实现全局模型的增量训练。
令D为当前批数据,D+和D-分别代表多数类数据集和少数类数据集。r为目标数据倾斜率,下采样D+将从随机抽取size(D-)/r个样本,记为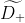 。然后将{
。然后将{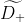 ,D-}作为全局增量模型的训练集。
,D-}作为全局增量模型的训练集。
在局部集成模型构建中,每一批数据对应一个局部集成模型,用来适应最新的数据分布。为了保证正负样本数量的平衡,也采用下采样的方式训练局部模型。为了降低因采样对模型性能造成的偏差,可采用多次下采样的方式,提升模型的预测精度。假设下采样的次数为T,那么将构建T个基分类器,这些基分类器的集成构成了当前批下的局部集成模型H。令hi为第i个基分类器,给定一测试样本x,局部集成模型H的预测结果为:
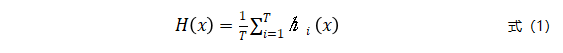
(3)针对概念漂移的自适应权重设计
为了捕获概念漂移,适应数据的概念变化,提出加权集成学习方法。假设当前时刻为t,需要预测第t批数据的标签。令Hk为第k批数据对应的局部集成模型,k
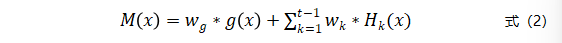
其中,wg为全局增量模型g的权重,wk为Hk的权重。Auto-LLE保留t时刻之前每批数据上训练得到的模型,然后通过自适应的权重调整以适应概念漂移。对于数据中存在的长期概念,则由全局增量模型负责学习。另外,全局增量模型的权重wg是固定不变的(默认为1/2),而第k批数据对应的模型权重wk是自适应变化的。权重主要取决于在验证集的上误差度量以及与当前时刻的窗口间隔。
在终生学习场景下,每一批数据都是按照时间先后顺序依次到达的。根据最近的数据最能反映未来这一基本假设,可以从最近一批的数据集中通过下采样得到验证集。令Vk为从第k批数据中采样得到的验证集,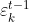 为第k批数据对应的模型Hk在Vt-1上的误差度量。
为第k批数据对应的模型Hk在Vt-1上的误差度量。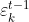 的计算公式如下所示:
的计算公式如下所示:
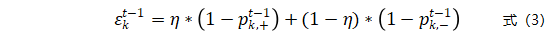
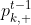 和
和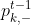 分别表示模型Hk在多数类和少数类中评估性能,参数η用来实现两者之间的平衡。如果η=1,则只关注在多数类中的误差度量,反之则只关注在少数类中的误差度量。默认情况下,η=1/2。当k=t-1时,如果
分别表示模型Hk在多数类和少数类中评估性能,参数η用来实现两者之间的平衡。如果η=1,则只关注在多数类中的误差度量,反之则只关注在少数类中的误差度量。默认情况下,η=1/2。当k=t-1时,如果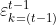 大于1/2,则说明模型Hk=(t-1)在Vt-1预测性能太差,需要在t-1批数据集上重新训练模型Hk=(t-1)。当k
大于1/2,则说明模型Hk=(t-1)在Vt-1预测性能太差,需要在t-1批数据集上重新训练模型Hk=(t-1)。当k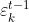 重新设为1/2。
重新设为1/2。
式(3)得到的误差度量的取值范围在0到1/2之间。通过式(4)将其映射到0到1之间。
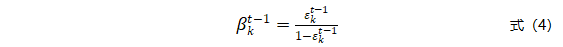
模型Hk的误差度量还和与当前时刻的窗口间隔相关。窗口间隔越大,则说明模型Hk对当前时刻的影响越小。因此需要进一步计算经过时间加权后的误差度量。采用Sigmoid函数评估时刻k对时刻t-1的影响因子,影响因子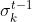 的计算公式如下:
的计算公式如下:
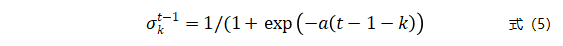
其中,a为Sigmoid函数的斜率。经时间加权后,模型Hk的误差度量 为:
为:
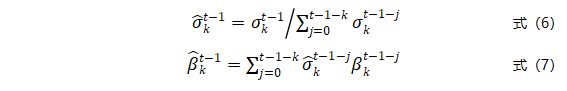
如式(7)所述,模型Hk的加权误差度量是在Hk验证集Vk到Vt-1之间所有误差度量的加权和,其综合考虑了模型Hk在第k批以及后续数据集上的性能表现。最终,模型Hk的权重为:
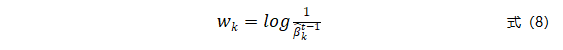
综上述,通过自适应调整模型Hk的权重,可以及时适应概念变化,捕获新的概念,降低旧的概念对模型的影响。针对概念漂移的自适应权重设计策略只需要保存所有的局部模型,以及每个局部模型在所有验证集上的预测性能,而无需保留历史数据。
算法验证
(1)数据集
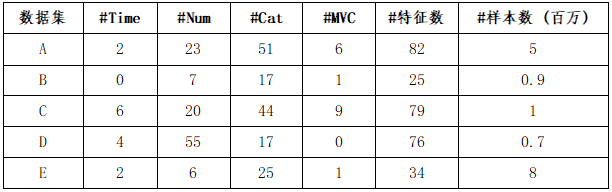
实验数据集来源于NeurIPS 2018 AutoML Challenge,共选取5个分类数据集。数据集特征多样,包含时间特征(Time)、连续特征(Num)、类型特征(Cat)以及多值特征(MVC)。另外,每个数据集根据时间先后顺序被划分为5批,每一批之间的数据存在概念漂移。所有数据集的元信息如表1所示。
表1 数据集元信息
(2)性能对比
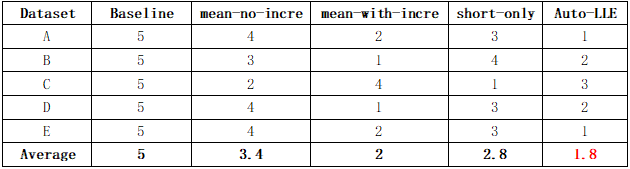
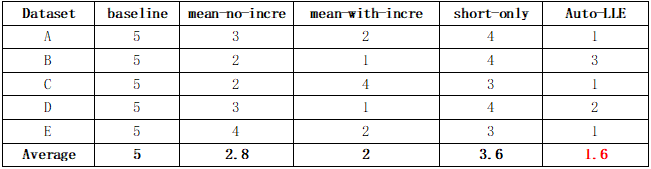
在AutoLLE算法框架中,最终模型是全局增量模型和多个局部集成模型的加权集成。而且,每个局部模型的权重可以自适应地改变,以便及时捕捉概念漂移。为了验证AutoLLE算法框架的有效性,实验设计了4种对比方法:
(1)baseline: 预测第t个测试批时,仅使用上一批的局部集成模型。
(2)mean-no-incre:关闭自适应权重设计功能,使用平均加权的方式对所有历史局部集成模型进行集成。另外,不使用全局增量模型。
(3)mean-with-incre:关闭自适应权重设计功能,使用平均加权的方式对所有局部集成模型进行集成。使用全局增量模型。
(4)short-only:仅使用局部集成模型进行集成,开启自适应权重设计用于捕获短期概念。不使用全局增量模型。
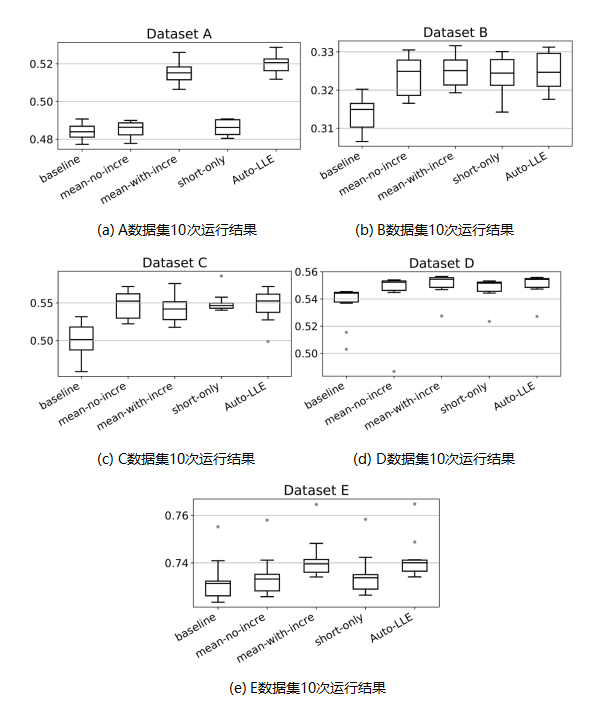
在AutoLLE中,全局增量模型和局部模型均采用LightGBM分类器。Sigmoid函数的斜率a为1,目标数据倾斜率r为0.5,每个局部集成模型包含5个分类器。所有对比方法采用同样的参数配置。每种方法运行10次,性能评估指标为AUC。每种方法的评价标准是所有测试批上的平均AUC。
表2和表3分别展示了所有方法在每个数据集上的平均性能排名和中位数性能排名。实验结果表明,AutoLLE的性能优于其他对比方法,印证了加权集成学习以及自适应权重设计策略的有效性。其中,AutoLLE优于short-only方法,验证了全局增量模型能够有效地捕获数据集中的长期概念。另外,AutoLLE优于mean-with-incre方法,验证了自适应权重设计能够有效地解决概念漂移问题。
表2 10次运行结果平均性能排名
导入依赖模块

传入首批数据

设置参数进行M1模型构建并训练

采用M1模型进行第二批数据预测

进行M2模型训练


进行加权集成模型结果预测

结果分析

为了解决终生学习场景下概念漂移问题,提出了基于自适应加权集成学习的自动化终生学习算法框架AutoLLE,通过集成全局增量模型和局部集成模型,能够有效地捕获长期概念和短期概念。另外,为了及时适应概念变化,提出了基于时间窗口和误差度量的模型权重自适应设计和调整策略。实验结果表明,AutoLLE能够高效自动地捕捉概念漂移,通过自动更新模型,提升模型预测性能。
AutoML自动化人工智能建模平台
江苏鸿程大数据研究院研发的AutoML自动化人工智能建模平台,无需人工干预,在模型性能不低于人工专家的前提下,能够大幅提高AI建模效率,从而降低AI使用门槛,让AI为人人所用
本文所述AutoLLE技术内容,参加了NIPS 2018举办的第三届AutoML国际大赛,在全球348支参赛队伍中(包括清华大学、北京大学、麻省理工学院、UC Berkeley等国内外知名高校以及微软、腾讯、阿里巴巴等科技巨头公司),我们PASA实验室团队取得国际第三名的优异成绩。

平台成功入选2020年国家工信部18个优秀人工智能技术产品之一(【新闻动态】研究院AutoML自动化建模平台入选国家工信部2020年人工智能优秀产品),入选江苏省工信厅大数据产品示范项目(【新闻动态】喜报!AutoML自动化人工智能建模技术与工具平台入选2021江苏省人工智能融合创新产品和应用解决方案名单)以及2022年“星光江苏”创新产品(研究院AutoML自动化AI建模工具平台荣获“星光江苏”数字经济新品优胜奖)

