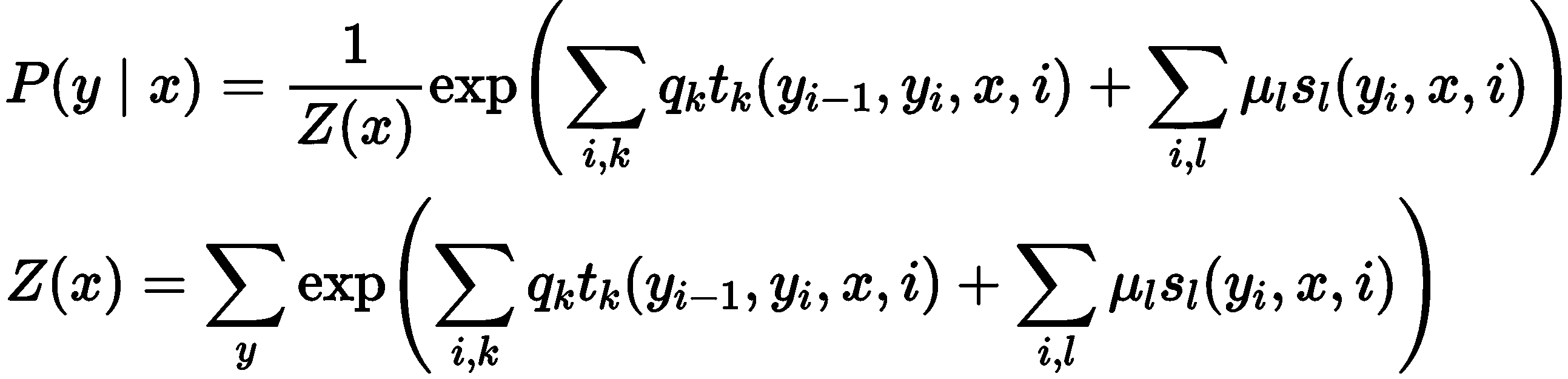前言
随着互联网新闻、政策文件、生物医疗、社交媒体等诸多领域文本数据的激增,如何从这些海量的非结构化文本数据中自动地识别并且抽取出结构化的字段对于各个行业进行数据高效检索与价值信息挖掘具有重要的应用价值。命名实体识别(Named Entity Recognition,简称NER)作为信息抽取技术的主要任务,在近年来受到产业界的极大关注。
本文将分别介绍命名实体识别的相关概念、识别过程、技术方法分类以及目前命名实体识别的前沿研究热点
命名实体识别相关概念
命名实体识别,旨在从非结构化的输入文本中识别特定的实体词汇,并且将识别出的实体词汇分类到预先定义的实体类型中。
例如,在图1中,给定例句1:“南京市3月20号共筛查出8名新冠肺炎检测呈阳性人员”。运用命名实体识别算法可以从文本中识别出“疾病”、“患者数量”与“检测结果”等信息。对于这些实体字段的自动化抽取可以为后续疫情防控分析提供数据支撑。

图1 命名实体识别应用案例
命名实体识别过程描述
命名实体识别主要过程包括:实体标签体系建立、数据标注与实体序列解码。实体标签体系需要结合实际应用领域进行创建,然后,基于实体标签进行实体标注,最后通过解码器得到最终的实体。具体介绍如下。2.1 实体序列标签体系(Tagging scheme)定义实体序列标签体系是解决命名实体识别的关键步骤。目前最常见的实体序列标签体系可细分为如下2种模式:将输入语句的每个字词标注为“B-X”、“I-X”或者“O”。其中,标签“B-X”表示该字词属于“X”类型的实体并且此字符位于该实体的开头位置。“I-X”表示字词所在的片段属于“X”类型并且此字/词在该片段的中间位置。“O”表示不属于实体的字词,即,其他字词。对于例句1:“南京市3月20号共筛查出8名新冠肺炎检测呈阳性人员”。在命名实体识别中,每个汉字字符对应的标签集合如图2所示。
|
Label_Set ={南: O 京: O 市: O 3:O 月: O 2:O 0:O 号:O 共:O 筛:0 查:O 出:O 8:B-NUM 名:O 新:B-ILLNESS 冠:I-ILLNESS 肺:I-ILLNESS 炎:I-ILLNESS 检:O 测:O 呈:O 阳:B-RESULT 性:E-RESULT 人:O 员:O }
|
图2 基于BIO实体标签的标注举例
其中,“NUM”表示实体类型为“数量”,“ILLNESS”表示实体类型为“疾病”,“RESULT”表示实体类型为“检测结果”。BIOES标签模式在BIO的基础上增加了单字符实体标签“S”与实体的结束字符标识标签“E”。其中,“E”表示这个词处于一个实体的结束位置,“S”表示某个字/词本身就可以被识别为一个实体。例如,对于例句1,在命名实体识别过程中,对每个汉字字符可以给出如图3所示标注结果。
|
Label_Set = {南:O 京:O 市:O 3:O 月:O 2:O 0:O 号:O 共:O 筛:O 查:O 出:O 8:S-NUM 名: O 新: B-ILLNESS 冠: I-ILLNESS 肺: I-ILLNESS 炎: E-ILLNESS 检: O 测: O 呈: O 阳: B-RESULT 性: E-RESULT 人: O 员: O }
|
2.2 实体序列解码
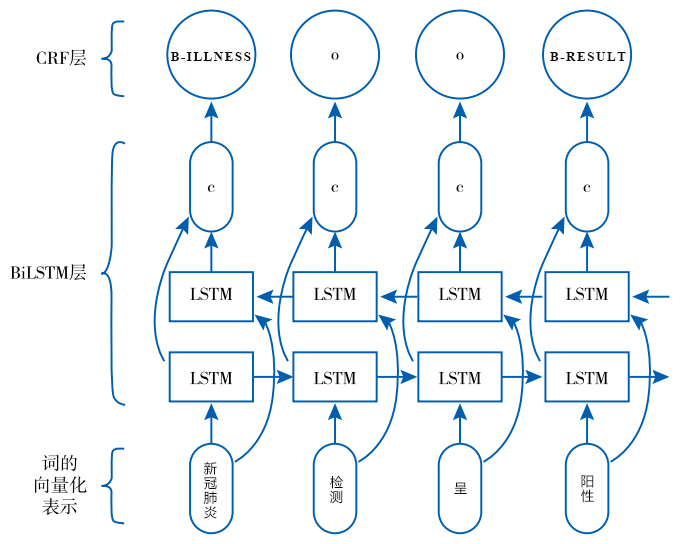
目前,主流的实体序列解码方法基于Bi-LSTM+CRF,其整体框架如图4所示。
双向长短时记忆模型(Bi-Long Short-Term Memory, Bi-LSTM)最早由 Hochreiter S[1]等人提出,是一种特殊的循环神经网络。该模型通过引入储存单元、输入门、遗忘门和输出门的控制机制,使其利用长距离历史信息的能力大幅提升。
Bi-LSTM 单元基于上一时刻的隐藏层信息与当前时刻的输入信息,计算遗忘门、输入门、输出门的值,再与上一时刻的储存单元信息进行整合,得到当前时刻的单元输出,同时对隐藏层信息和储存单元信息进行更新,作为下一时刻 Bi-LSTM单元的输入。在实体序列解码过程中,对于每一个输入的字/词,模型会输出一个k维向量,k是最终实体类别的标签数目,向量的每一个取值代表当前词语被分到相应类别的概率,预测时取最大概率对应的实体类别作为当前词语的标注。条件随机场(Conditional Random Field, CRF)是一种序列解码算法。在对实体序列解码过程中同时考虑词语本身、词汇上下文特征以及已解码的实体类型对于后续实体解码的影响。条件随机场其工作原理为给定一组输入随机变量的条件下,输出另一组随机变量(即,每个字词对应的实体标签)的条件概率分布,其计算公式如下:
其中,Z(x)为规范化因子。x指原文本序列变量,y为实体标注变量,P(y|x)是在给定x的条件下输出序列y的条件概率分布。条件随机场可考虑多种文本特征,这是因为其有两类特征函数,第一类是状态特征函数sl(yi,x,i),即实体类别只和当前文本有关;第二类是局部特征函数tk(yi-1,yi,x,i),其可考虑外部特征(如词性、大小写、上下文等)对实体类别的影响。
基于最大化条件似然对L(p(y|X))进行学习,公式如下:
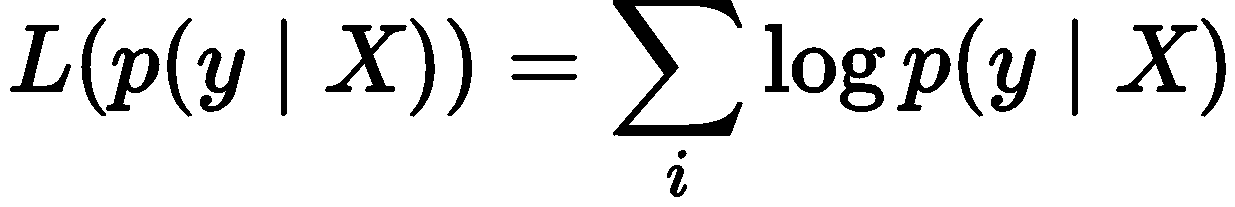
解码时,将评分最高的序列预测为实体的输出序列yo,计算公式如下:
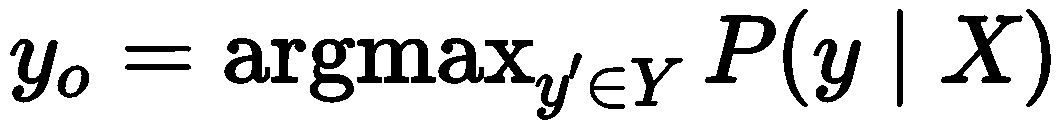
命名实体识别技术方法分类
考虑不同的应用领域对于命名实体识别算法存在不同的偏好,因此,我们对现有的命名实体识别相关理论、方法与技术进行分类,总结如图5所示。
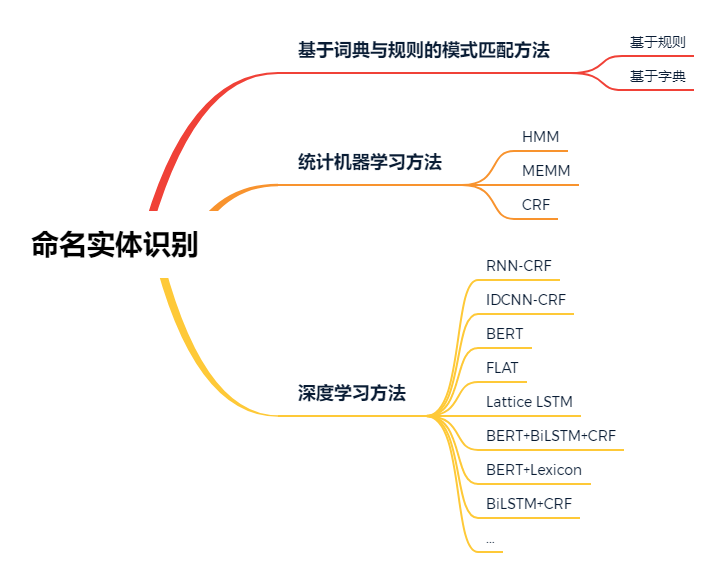
图5 现有命名实体识别技术分类
(1)基于词典和规则的模式匹配方法[2]
在NER中,基于模式匹配的方法最早得到应用。该方法提取专家知识并将其转换为匹配规则,具体过程为:
· 维护一个数量较大并且全面的词典。对于某些垂直领域,例如,有学者构建了医学实体数据词典进行医学NER[3]。若文本中有实体未被词典收录,则手动录入词典以供下一次识别使用。
· 在完成词典构建的基础上,增加实体构造规则,据此提取实体。典型的规则包括关键词、位置词、中心词等元素。例如,中文译名NER中利用普通人名的构成规律,例如,全称“[姓+名]”,代称“[姓+职位]、[老(小)+姓]”等模式进行识别[2];面向化学物品识别的化学NER则利用化学物质的构成模式:“化学介词+化学词头+化学符号”,使用正则表达式对化学物品进行专有名称识别与提取[2]。
基于词典与规则的模式匹配方法的命名实体识别准确率较高。某些应用领域通过枚举所有可能的实体构造规则可以使得命名实体识别与抽取的准确率超过95%。因此,基于词典与规则的模式匹配方法仍是某些应用领域的首选。但是,这类方法的实体识别规则的制定依赖于领域专家,并且领域之间难以进行复用。同时,领域词典需定期维护,不断涌现的新兴实体与实体构造的不规则性使构造完备的词典变得困难重重。因此,基于机器学习的命名实体识别相关理论、方法与技术开始受到关注。基于统计机器学习进行命名实体识别的一般过程为:对待识别的文本进行序列标注,构造特征模板提取输入特征,基于序列标注进行序列解码模型的训练,将训练好的模型运用到具体文本中实现命名实体的自动识别与抽取。序列解码模型是整个命名实体识别过程中的关键环节,目前常用的解码模型包括:隐马尔可夫模型(Hidden Markov Model,HMM)、最大熵模型(Maximum Entropy Model,MEM)与条件随机场模型(Conditional Random Fields,CRF)。基于统计机器学习的命名实体识别准确性相对有基于模式匹配的方法更高,但是同时也依赖于手工构造具有良好领域泛化性能的特征模板。因此,在后续命名实体识别技术的发展中,基于深度学习的方法,能够自动编码输入特征的命名实体识别方法逐渐成为主流技术。上述分析表明,原始文本的上下文特征对于命名实体识别的准确性至关重要。但是,构建上下文特征需要大量的领域知识。随着基于深度学习的方法在自然语言处理上的广泛应用,特征提取过程也实现了自动化。基于深度学习的命名实体识别方法直接以字词向量作为输入,通过深度神经网络模型(例如,Bi-LSTM、RNN、Transformer等)学习文本的上下文信息,而不需要手工设计特征来捕捉语义信息。
相比于统计机器学习模型,基于深度学习的NER方法取得了更好的准确性表现,但是仍然存在一些亟待解决的难点问题:
· 不同语言环境下的命名实体识别问题。例如,中文命名实体识别中因边界词识别歧义而导致的实体识别歧义问题;
· 不同实体结构造成的模型编码失效问题。例如,对于嵌套实体、非连续实体,现有的命名实体识别方法难以进行准确识别;
· 基于深度学习的命名实体识别方法依赖于大规模语料集,对于缺少数据标注的领域问题的泛化性能亟待进一步优化。
命名实体识别前沿研究热点
在广大应用场景的驱动下,命名实体识别技术的发展如火如荼,一些前沿研究热点值得进一步探索与应用。
在中文命名实体识别的过程中需要对实体在句子中的边界位置与实体类别进行识别。与英文相比,中文命名实体识别的难点在于:
· 中文的字词之间、实体之间没有显式的边界分隔符。不同的实体边界识别结果会导致不同的实体识别结果。
· 中文实体的数量庞大并且实体属类也更加模糊,导致对中文命名实体进行识别与抽取时存在歧义问题。因此,实体消歧也是中文命名实体识别面临的一大挑战。
为了解决这些问题,Zhang 和Yang[4]首先研究使用提出了一种基于LSTM模型与字符间格结构的变种(Lattice-LSTM)模型。该模型利用外部词典中的词汇信息,建立字符之间的关联关系,从而进行实体边界识别。与基于字符的方法相比,该方法显式的利用了外部词典中词与词之间的序列信息,因此,能够缓解实体边界的识别歧义问题。Li等人[5]提出了FLAT(Chinese NER using Flat-lattice Transformer)模型,基于平面晶格结构与Transformer模型,通过位置编码来捕获词边界信息,缓解中文命名实体识别的实体边界歧义问题。非连续命名实体识别,即实体可能由不连续的单词序列组成。不连续NER在许多实际场景中普遍存在。例如,在政策服务领域,在获取政策实体的过程中经常存在非连续的实体。如图6所示,句子(1)展示了一个简单的实体结构,而句子(2)则展示了一种非连续的实体结构。在句子(2)中,“技术合同输出额和吸纳额”中间被“和”分隔了,一般方法只能识别“技术合同输出额”,而“技术合同吸纳额”这一非连续实体则会被忽略。这种非连续的实体同样在基因工程与生物医学领域的文本处理由为常见。
为了解决非连续命名实体识别的难点问题,Tang等人[6]扩展了现有的实体标签体系,将BIO标记方案扩展到更复杂的标签方案——BIOHD。其中,BIOHD标注体系可以表示具有不连续结构的实体。相比于BIO标注体系,BIOHD引入额外的两个标签“H、D”,其中“H”表示同时被多个非连续实体共用的部分(称为“实体头”),“D”表示不被多个非连续实体共用的部分(称为“非实体头”)。此外,还存在基于潜在实体组合[7]、基于结构化多标签分类[8]等面向非连续实体的命名实体识别算法。嵌套实体也是命名实体识别过程中经常遇见的一种情况,即,不同的实体可能存在包含关系,一个短实体可能包含在一个长实体的内部。例如,“南京长江大桥”属于“位置(Location)类”的实体,而“南京长江大桥” 中的“南京”同时也是“地理(Geography)类”实体。对于这种具有嵌套结构的命名实体,传统的基于序列标注的命名实体模型是难以直接有效地处理的。为了解决嵌套命名实体识别的难题,近些年来,相关学者进行了一些有益的探索。Ju等人[9]提出了一种基于堆叠LSTM-CRF的嵌套NER算法,首先识别嵌套结构中的内部实体,然后识别外部较长的实体。Wang和Lu[9]等人则构建了一个超图(hypergrapch)来捕捉句子中所有可能提到的实体结构,并且通过建立所有潜在候选实体节点之间的路径(hyperpath)实现嵌套命名实体的识别与抽取。基于深度神经网络模型的命名实体识别方法通常依赖于大规模的标注数据集。当数据资源不足时,模型无法充分学习潜层语义特征,同时,容易在小数据集上过拟合[11]。因此,目前的方法很难迁移用到缺少标注数据的垂直应用领域,如社交媒体、政策服务、生物医学等。为了解决上述问题,面向小样本的命名实体识别工作正逐步受到学者与工业界的关注。Ziyadi等人[12]提出一种基于原型的小样本命名实体识别方法,主要思路是将少量已有标注的样本作为原型,基于原型识别出大量未标注数据中相关的实体。Cui等人[13]则基于提示学习(Prompt learning),将命名实体识别任务转换成基于预训练语言模型的掩码词汇预测任务,利用语言模型完成小样本场景下的命名实体识别任务。
综上所述,在命名实体识别领域,综合运用基于迁移学习、半监督学习、远程监督学习、主动学习、提示学习以及预训练语言模型的方法解决垂直应用领域有标注数据匮乏难题的研究方兴未艾!
参考文献
[1] Hochreiter S, Schmidhuber J. Long short-term memory. Neural computation, 1997, 9(8): 1735-1780.[2] 焦凯楠, 李欣, 朱容辰. 中文领域命名实体识别综述. 计算机工程与应用, 2021, 57(16): 1-15.[3] Sevenster M, van Ommering R, Qian Y. Automatically correlating clinical findings and body locations in radiology reports using MedLEE. J Digit Imaging. 2012, 25(2).[4] Yue Zhang and Jie Yang. 2018. Chinese NER Using Lattice LSTM. ACL, 2018, 1554-1564.[5] Xiaonan Li, Hang Yan, Xipeng Qiu, and Xuanjing Huang. FLAT: Chinese NER Using Flat-Lattice Transformer. ACL, 2020, 6836-6842.[6] Tang B, Cao H, Wu Y, Jiang M, Xu H. Recognizing clinical entities in hospital discharge summaries using Structural Support Vector Machines with word representation features. BMC Med Inform Decis Mak. 2013.[7] Bailin Wang and Wei Lu. Combining Spans into Entities: A Neural Two-Stage Approach for Recognizing Discontiguous Entities. EMNLP, 2019, 6216-6224.[8] Tang B, Hu J, Wang X, et al. Recognizing Continuous and Discontinuous Adverse Drug Reaction Mentions from Social Media Using LSTM-CRF. Wireless Communications and Mobile Computing, 2018.[9] Meizhi Ju, Makoto Miwa, and Sophia Ananiadou. A Neural Layered Model for Nested Named Entity Recognition. NAACL, 2018, 1446-1459.[10] Bailin Wang and Wei Lu. Neural Segmental Hypergraphs for Overlapping Mention Recognition. EMNLP, 2018, 204-214.[11] Fritzler A, Logacheva V, Kretov M. Few-shot classification in named entity recognition task. Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing. 2019: 993-1000.[12] Ziyadi M, Sun Y, Goswami A, et al. Example-based named entity recognition. arXiv, 2008, 10570, 2020.[13] Leyang Cui, Yu Wu, Jian Liu, Sen Yang, and Yue Zhang. 2021. Template-Based Named Entity Recognition Using BART. ACL, Findings, 2021, 1835-1845.