前言
近些年,随着机器学习在各行各业的落地应用,大家对机器学习的需求也在快速增长。然而,机器学习建模比较依赖专家经验。当非机器学习专家面对复杂的机器学习任务时,很难发挥机器学习的作用,这也是阻碍AI有效落地的关键因素。因此,人们非常需要一个易用且无需专家经验的机器学习方法。自动化机器学习就是为了解决这个问题而出现的。
目前,自动化机器学习需要解决的问题可划分为很多子问题,比如特征工程、超参优化、模型选择等等。其中自动化特征工程是自动化机器学习一个比较重要的细分领域。这是因为建模的效果比较依赖高价值的特征,而挖掘特征又是一个比较耗时并且需要经验的过程。所以大家对自动化特征工程有较强的需求。
业务场景分析
机器学习建模过程中,需要大量的特征工程,特征工程可以被看作是为了减少建模误差来增加或者删除特征的过程,涉及到给定特征集合的转换,通常使用数学变换函数进行转换。为了对患者的心脏病预测问题进行建模,考虑到已有下列特征:身高、体重、腰围、臀围、年龄、性别等。尽管给定的特征对该分类问题都具有较大的相关性,但是通过身高和体重计算得到的 BMI 指数这一组合特征能够使分类准确度得到更大的提升。从上面的例子可以看出,机器学习建模比较依赖寻找到的高价值特征,相比于更复杂的模型,这种高价值特征可以带来更大的效果提升。同时特征工程对人为决策因素有较强的依赖,分析人员为了寻找高价值特征,需要根据专家经验在给定数据集上进行特征变换和特征组合,并且需要通过反复实验来确定构造的特征确实符合当前任务。同时,因为不同特征可以选择多种不同的变换函数,以及特征之间的组合也有很多种可能的情况,最终将导致搜索空间过大,以至于无法通过穷举的方式来寻找高价值特征。所以人工特征工程不仅涉及专家经验和领域知识,还是一个漫长的反复实验的过程。通过对各种机器学习建模场景进行梳理,对于自动化特征工程主要有以下几个需求:需求1:能够显著提升模型性能。特别是针对不同的数据集,均能够较好的提升模型性能。需求2:能够显著减少人工干预。能够由策略自主控制,尽量减少人为因素干预,避免过度依赖专家经验。需求3:能够比人工建模更高效。和人工构建新特征过程相比,能够更快的挖掘潜在高价值特征。
需求4:能够对新特征进行人工解释。构建的新特征能够通过规则进行解释,以便分析人员理解新特征在业务上的含义。
解决方案
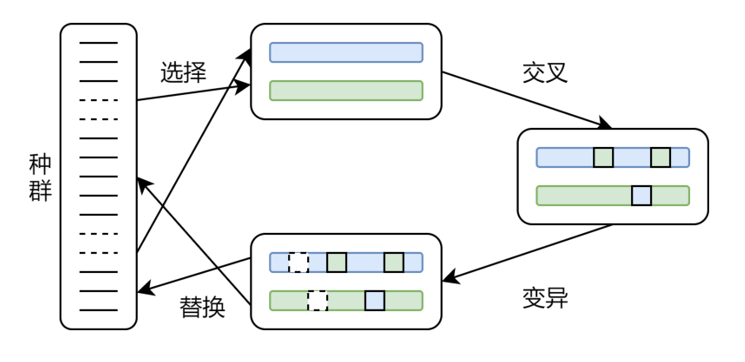
基于进化算法的自动化特征工程(Evolutionary Algorithm Automated Feature Engineering),简称:EAAFE。是一种先进的自动化特征工程方法。该方法适用于大搜索空间的最优化问题,具有较好的鲁棒性。进化算法是一类通过模拟自然界生物自然选择和自然进化的随机搜索算法。在自然界生物周而复始的繁衍中,适应环境的生物个体得到保留,适应性差的个体生物被淘汰,优秀的生物个体的基因会经过重组、变异等操作得以保留,从而实现进化。进化算法简化了这一复杂过程,抽象了一组数学模型,使用更简单的编码方法来表示复杂现象,通过模拟进化过程实现启发式搜索,最终可以在较大的搜索空间中找到全局最优解。
进化算法图示:
EAAFE算法的总体流程:
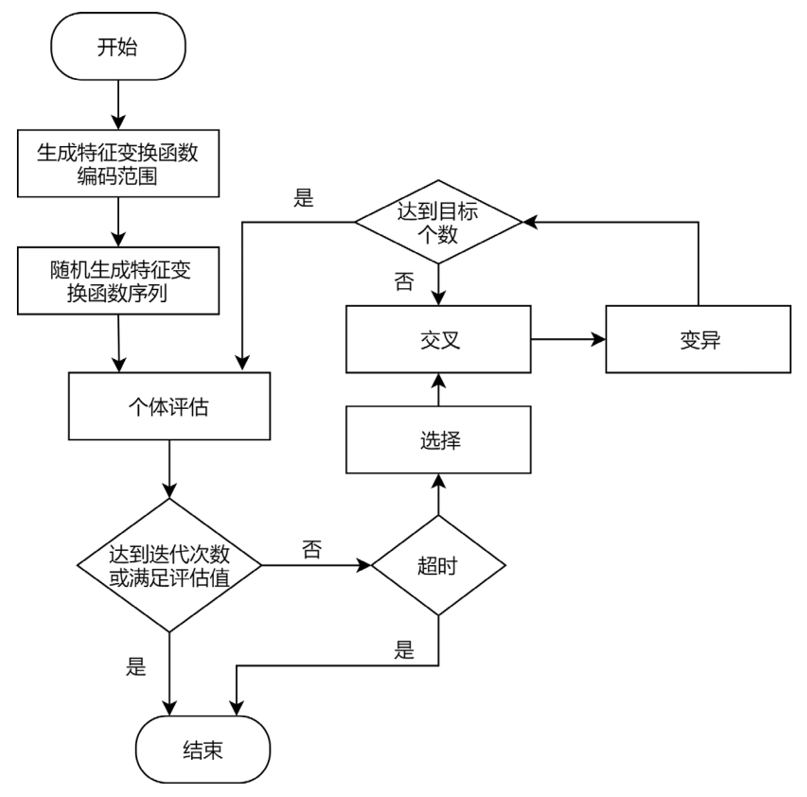
EAAFE执行步骤主要包括:(1)生成特征变换函数编码范围;(2)随机生成特征变换函数序列;(3)个体评估;(4)选择;(5)交叉;(6)变异;(7)进化。
步骤一:生成特征变换函数编码范围。根据数据集的特征信息和相应的候选特征变换函数数量,计算得到每一个特征变换函数的编码,并将不同特征类别的变换函数的编码映射到不重合的整数区间范围。
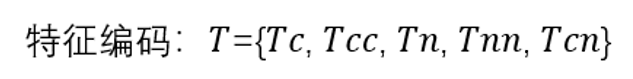
在以上编码中,Tc表示对离散型特征做一阶变换;Tcc表示同时对两个离散型特征做变换;Tn表示对数值型特征做一阶变换;Tnn表示同时对两个数值型特征做变换;Tcn表示在离散型特征和数值型特征之间做变换。步骤二:随机生成特征变换函数序列。根据约束条件随机生成若干个体,每个个体包含多个特征变换函数序列,与原始数据集中的多个特征一一对应。如下图所示:f为特征编号,t为特征变换序列。
步骤三:个体评估。将个体中的多个特征变换函数序列解码后,对原始数据集进行特征变换,将变换后的特征与原始特征拼接得到新的数据集,在新的数据集上训练机器学习模型,并将训练后的机器学习模型的预测性能作为种群中个体的适应度。步骤四:选择。根据适应度,使用轮盘赌选择策略独立地从当前种群中选择若干个体作为母体,适应度较高的个体可能被多次选中,并且为了保持种群基因多样性,表现普通的个体也有概率被选中。步骤五:交叉。根据两点交叉策略,首先将选定的若干母体进行两两配对,然后在特征变换函数序列中随机选择两个交叉位置,将交叉位置之间的编码互换,从而生成子代个体。
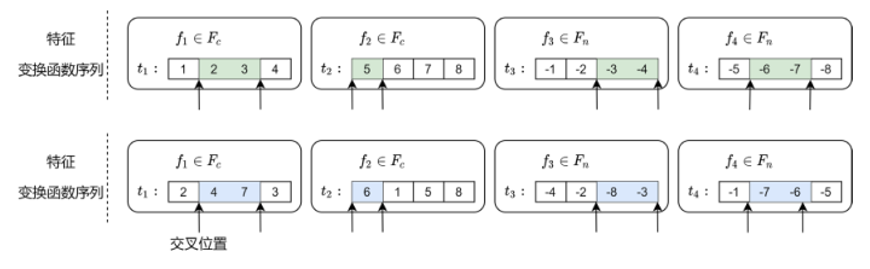
步骤六:变异。对子代个体中的特征变换函数序列的每个编码进行遍历。在遍历过程中生成[0,1]之间的随机数,并通过与变异概率阈值对比来决定是否对该编码进行变异。对于变异过程,首先需要确定当前特征的类别,然后从相应的编码空间范围内随机选择一个编码对原编码替换。
步骤七:进化。通过交叉变异后的子代组成新一代种群,继续重复步骤(3)~(6),直到满足种群进化停止条件,并返回最优个体。停止条件通常有达到进化迭代次数、达到预定的评估值要求,以及计算超时。
应用案例
以下是银行信用贷款评估建模中的自动化特征工程应用。信用评估是机器学习常见的应用领域,在银行贷款审核、客户违约风险预测等方面有重要的应用。本案例是关于贷款申请客户风险评估的建模,目的是根据申请人提交的信息对其进行违约风险预测。数据集介绍:该数据集是客户是否违约的一个分类数据。样本标签为二分类数据,即是否发生贷款违约。该数据集的总样本数量为1000个,特征数量为20个。特征包含个人的基本息和行为数据,比如年龄、工作时间、住宅、贷款目的、贷款数量等等。为了对比自动化特征工程的应用效果,这里对评估方法进行以下设定。自动化特征工程建模:使用EAAFE特征变换之后的数据进行建模。机器学习模型:为了降低模型对特征工程对比效果的影响,因此统一使用随机森林进行建模,并保持默认参数。评估指标:因正负样本均衡度较好,所以使用准确度进行评估。数据处理方法:为了保证对比的客观性,这里使用相同的测试集划分,使用相同的数据清洗方法(包括数据标准化),且不对数据进行特征筛选。
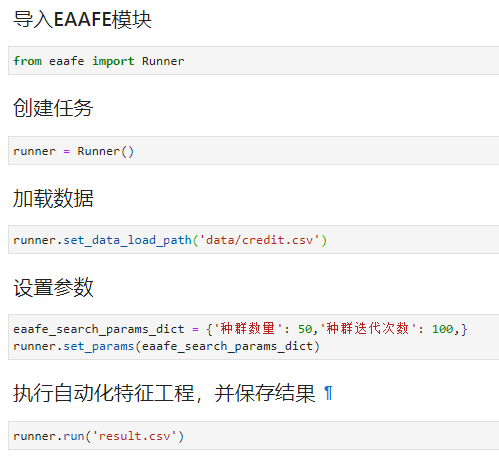
在进行基本的设定后,开始基于我们的AutoML自动化建模软件SDK开发包,通过API调用EAAFE算法进行自动化特征选择,进行自动的特征组合变换,特征变换后的数据以csv的形式导出并保存。
在经过以上步骤得到新特征后,再分别使用随机森林对原始数据和EAAFE特征变换后的数据进行建模。最终随机森林建模的评估结果为:原始数据建模的准确率74.1%,而经过EAAFE特征变换后的数据建模准确率达到80.3%,准确率提升了6.2%。可见EAAFE特征变换的有效性。
结合业务的实际意义来看,以上部分新特征比较符合业务逻辑。所以从模型准确率角度和业务角度来看,均可以证明EAAFE自动化特征工程的有效性。
总结
自动化特征工程在工业界和学术界都有较大的应用价值,并有以下几点优势:(1)在传统的结构化数据集上能够挖掘出高价值特征。(2)面对海量的搜索空间,能将特征工程这一繁琐过程自动化,将数据分析人员从反复试错的过程中解放出来,机器学习模型构建更加迅速。(3)排除人工因素的影响,构造的新特征对模型效果更具有鲁棒性。
AutoML自动化人工智能建模工具平台
目前,行业大数据分析与人工智能应用面临较大的瓶颈和制约,缺少AI技术人才,AI建模技术门槛高、大量依赖专家经验,建模周期长、成本高、效率低。
江苏鸿程大数据研究院研发的AutoML自动化人工智能建模工具平台,内置了南京大学PASA大数据实验室自主原创、国际先进的AutoML技术,用户仅需给定数据和预算时间,无需人工干预,平台即可自动化实现机器学习流水线的自动化设计,将数据预处理、特征选择、模型选择以及超参数调优等步骤,交由AutoML平台自动完成,从而实现AI模型的自动化构建。在模型性能不低于人工专家的前提下,能够大幅提高AI建模效率,从而降低AI使用门槛,让AI为人人所用。