
2020-06-09
分享到前言
大家好,我是江苏鸿程大数据研究院跨平台统一分析处理与可视化编程平台产品组的李一繁,今天来给大家分享从机器学习到AutoML的一些内容。
AutoML是Automatic Machine Learning的缩写,所以在了解AutoML之前,我们必须要对Machine Learning要有所认识。此外,我还想给大家多介绍一点关于机器学习领域的背景故事,让我们一起开始吧。
什么是机器学习
机器学习(Machine Learning)是关于计算系统使用的算法和统计模型的科学研究,这些算法和统计模型不使用明显的指令,而是依靠模式和推理来有效地执行特定的任务,它被视为人工智能的一个子集。现在我们随处可见的人脸识别、机器翻译等应用都是机器学习的体现。
为了帮助大家直观的理解机器学习为什么能够产生这些成功的应用,我找了机器学习入门级的一个案例——手写数字集和KNN,这也是机器学习界的”Hello World”。
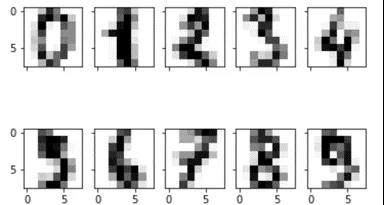
如图所示,手写数字集是一个拥有上千张手写数字的照片的数据集,这些照片已经有人帮我们提前打好了标签,即每张照片属于0-9的哪个类别。我们的目的就是通过这上千张照片去训练一个比较准确的机器学习模型,从而在未来帮助我们自动识别图片中的数字,节省我们的人力成本。大家现在看到的车牌识别、OCR软件就是这一类的模型。
有了数据集、有了我们的目的,下一步就是要有一个能够解决这个问题的模型了。对于这种问题,有很多传统的机器学习模型可供我们选择,这里我给大家介绍一个最简单的机器学习模型——KNN(K-Neighbors-Nearest)。
和我们人类的是非观一样,机器学习也有自己的是非观思想。KNN这种思想非常简单,就是“物以类聚,人以群分”。当一个新的数据需要我们预测它属于哪个类别的时候,KNN会遍历所有的老数据,从中找到离它距离最近的K个数据,根据这K个数据中最多的标签来决定我们这个新数据属于哪一类别。


比如图中有8个几何体,其中3个红色的圆柱体,代表着一个贷款违约的用户,还有4个代表着不违约用户的三角形。现在来了一个想要办理贷款的新用户——这个灰色的立方体,KNN是如何预测该用户是否违约,从而帮助银行决策是否办理呢?
首先,我们需要输入一个参数K,比如我们输入K=1,此时KNN会遍历整个数据集,它会发现离我们灰色立方体最近的是绿色三角形,所以KNN就会告诉银行的信贷员:这个用户可以贷款,因为之前有个人和它情况相似最后也如期还款,所以我们可以信赖。
但是当K=3的时候,KNN会发现离灰色立方体最近的有2个红色的圆柱体和1个绿色三角形,根据少数服从多数的原则,KNN就会得出该人不可靠的结论。但是当K=7的时候,情况又反了过来。

大家不难发现,这个K取不同的时候,我们得到的结果完全不一样,这是因为KNN的思想就是“人以群分”,它会找到离需要预测的新数据最近的K个数据,将他们看成“一群人”,然后根据这群人最多的那些类别作为新数据的标签。当K过大,群就更大,反之则反。
K并不是越大越好,它是需要我们自己手动去调的参数,我们通常将这种参数称为超参数。对于超参数的调整,就需要利用到我们之前已经打了标签的数据集,我们可以分出一些比如70%的数据集作为有标签的老数据,再分出30%的数据集,暂时不看它的标签作为我们的“新数据”。之后我们就先拿这种“新数据”去预测,将结果与“新数据”的原来的标签对比,从而得到我们是否预测正确的结论。
知道了KNN的原理,那么为什么手写数字集可以运用这个模型呢?手写数字集难道不是一堆照片吗?其实大家用过制图软件的同学就知道,我们每张照片都是由颜色不同的像素点组成,对于颜色,在计算机中我们一般使用RGB三原色的组合来表示,由三个0-255的数字组成的。
而对于手写数字集这种照片,它是纯黑白的8像素点*8像素点组成的图片,所以结构更加简单。对于每张图片,我们都能将其转化为1行64列的0-255组成的数据。对于这种将非数字型的数据给数字化的过程,我们将其称为结构化,之所以机器学习的模型能够应用在这么多的领域也是得益于越来越多的结构化技术。
经过这样的转换之后,当来一个新的1行64列的数据,KNN就会遍历所有的老数据,计算这个新数据和所有老数据的距离,从中排序选出最近的K个数据。这个距离就是初中数学坐标系中的两点距离即欧几里得距离,不一样的是我们这里的向量不是二维,而是64维。
手写数字集不仅能用KNN,而且正确率高达99%,之所以不是100%是因为有些人写出来的数字普通人也分辨不出来。KNN在数字甚至字母识别上的应用,能够减轻我们大量的人力成本,提升我们社会运行的效率。
为什么能这么有效?是因为大家在写同一个数字比如0的时候,中间一点的墨迹就是会少一点,这样那里的值就是小点,反之两边的值就会大一点。所以在拉成64列的数据后,对应位置相减平方和加总,这样的结果也小点,即近一点。如果两次墨迹位置轻重完全一样,距离甚至可以为0。
但是换了一个场景之后,KNN就无法解决了,因为它“看待世界”的方式有它的局限。这也是为什么我们经常强调没有包打一切的模型,只有最适合没有最好。
机器学习和大数据
通过上面的案例,我们发现虽然我们讲的是机器学习,但是在机器学习中还有同样重要的一个角色——数据。在上面的案例中,假如我们只有一个老数据,那么无论怎么去计算,新数据始终会被归到一类。模型没有好数据就好比厨师没有原材料,厨师再厉害也无法有作为。
李飞飞教授早期就认识到数据在机器学习中起到的重要性,早在2006年就开始着手构建ImageNet数据集,2009年正式诞生,并在此基础上开始图像识别竞赛。
这是个空前庞大且质量很高的数据集,它含有1500万张照片、涵盖了22000种物品。这些物品是根据日常英语单词 进行分类组织的。无论是在质量上还是数量上, 这都是一个规模空前的数据库。举个例子,在'猫'这个对象中, ImageNet有超过62000只猫 长相各异,姿势五花八门, 而且涵盖了各种品种的家猫和野猫。
李飞飞教授的想法是非常有道理的,比如孩子很小的时候就能分辨周围的物体,而这时的它们应该还是一个能力很弱的“分类器”,之所以能够达到这样的效果是因为训练的数据足够多——“如果你把孩子的眼睛看作是生物照相机, 那他们每200毫秒就拍一张照。——这是眼球转动一次的平均时间。所以到3岁大的时候,一个孩子已经看过了上亿张的真实世界照片。这种“训练照片”的数量是非常大的。”
果然,ImageNet项目获得了巨大的成功,直到2017年落幕,其间产生了AlexNet、Inception、VGG、ResNet等经典模型,推动了深度学习、CV(Computer Version,计算机视觉)的技术和产业发展。
如今机器学习能够如此蓬勃发展,很大程度得益于这么多年累积、并在不断被开发转化的大数据。没有如今的海量数据,机器学习的模型再好,也终究会在历史的长河中蒙尘,比如深度学习。
机器学习和深度学习
深度学习的前身是人工神经网络(Artificial Neural Network, ANN) ,又称为多层感知机(Multi-Layer Perceptron, MLP)。早在1958年,Frank Rosenblatt就提出没有隐藏层的MLP,发展到现在已经遍地开花的深度学习现实应用,神经网络已经成为机器学习家族最强大的学习器,由于其效果好、架构特点突出,神经网络更是“自立门户”,开辟出一门深度学习的学科。
之所以叫神经网络,是因为它模仿了了生物上神经元之间传递信息的过程。人体内有上百亿个神经元,大脑处理信息的过程都依赖于神经元对信息的传递、处理,只要通过某种连接和计算形式模仿神经元的运作,就可能模拟人的大脑这个非常强大的分类器的运行。
如上图所示,当一张照片的信息变成像素点后传递,每个点有RGB三个数值,所以我们首先需要3个细胞收集,之后我们将这个信息乘上一定的权重ω,并通过某种转换。再模拟轴突向树突传递的方向向后面一层的神经元传递。最后进行汇总和预测判断。随着大家发现中间的层数越多即层数越深,模型的效果有时候就越好,所以神经网络慢慢就被称为了深度学习。
不仅结构的特殊性,深度学习的目标也与传统的机器学习不同,一般来说,机器学习的三大目标是:效果、速度、可解释性。神经网络将效果视为唯一目标,为了这个目标不吝收集千万上亿的数据集、构建千万上亿的神经单元、调用几百上千台装有GPU、TPU的高性能计算机机群,即使在这样充分的准备下强如Alpha Go也要训练好几天才能成为围棋大师,的确是将速度抛诸脑后。同时,由于网络结构复杂,在当前几乎完全丧失了可解释性。
我们来思考一个问题,为什么深度学习有效?如上图所示,这是一个传统的机器学习处理图像识别的方法,一般会用PCA、SVD对图像进行降维,去除掉脸部的细节噪声,而保留脸的轮廓,然后再用SVM这样的算法进行分类。
但是深度学习吸收了图像领域一些处理图像的方法,比如图像金字塔、卷积操作等。利用卷积层、池化层这样的组件,模拟了我们识别人脸的过程,即并不是一个点一个点的识别,而是一块区域一起进行了汇总识别,从而将低层的特征转化成更加抽象的高层特征。最后,利用高层特征进行分类或者预测。这也是深度学习的强大之处:将特征提取和分类问题在一个神经网络得到解决。
深度学习CV的案例
由ImageNet海量已标注的图片数据帮助,深度学习在CV领域获得了巨大的成功。
比如图中AlexNet诞生于2012年,它包含2400万个节点、1亿4千万个参数和150亿个连接。AlexNet也是ImageNet项目诞生后的深度学习第一个有代表性的模型。之所以叫Alex是因为发明人是Alex,他当时在Hinton的实验室工作,Hinton也是深度学习三巨头之一,于去年获得了图灵奖。


深度学习为什么起作用

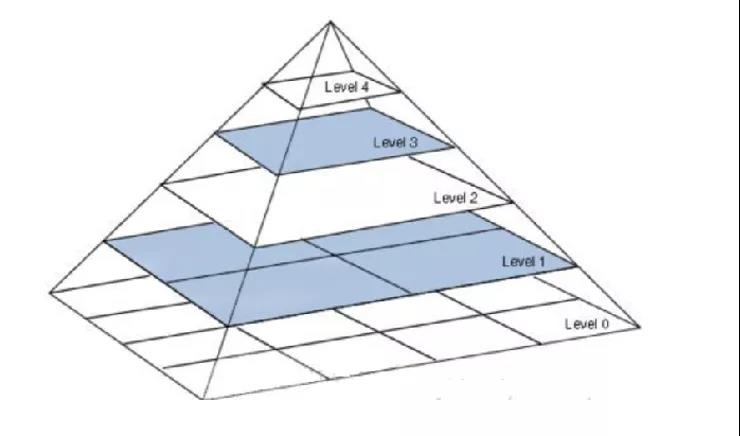
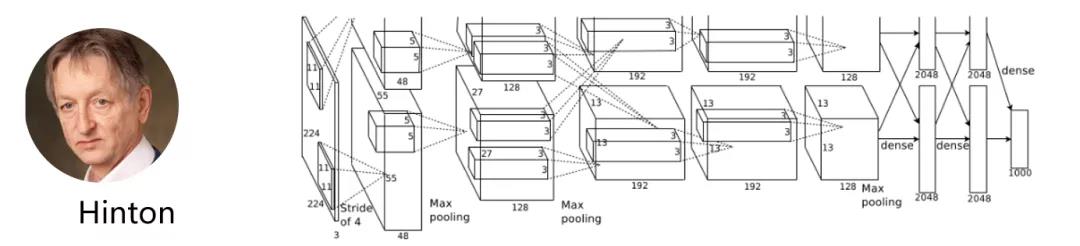
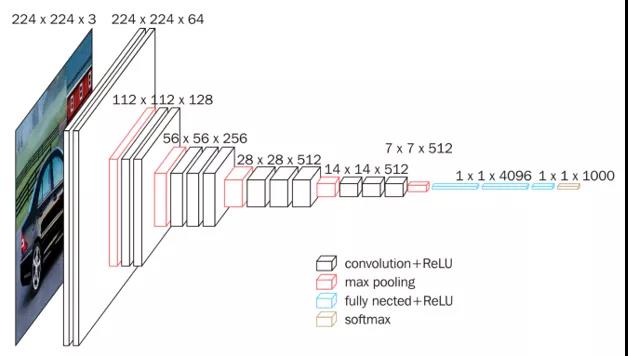
VGG是由Simonyan 和Zisserman(牛津大学计算机视觉组和Google DeepMind公司研究员)中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写。该模型参加2014年的 ImageNet图像分类与定位挑战赛,取得了分类任务的第二名。
该网络一共有16个训练参数的网络,它的兄弟版本如上图所示,清晰的展示了每一级别的参数量,从11层的网络一直到19层的网络。VGGNet网络结构简洁,迁移到其他图片数据上的泛化性能非常好。VGGNet现在依然经常被用来提取图像特征,比如在目标检测的应用。
深度学习CV在目标检测的应用
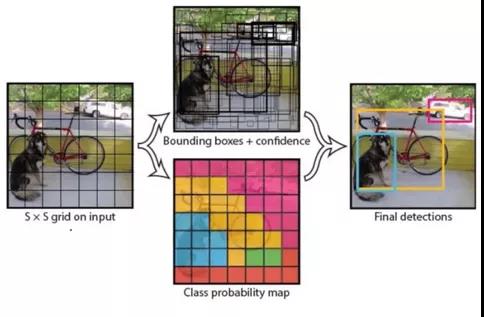
由于在图像识别领域的巨大成功,更切合实际场景的CV应用即目标检测类的深度学习算法也应运而生,如SSD、Yolo等。它们的原理是在原本图像分类的基础上加上了Bounding-Box,比如图中画了大量的Bounding-Box后根据置信度生成了每个像素点的类别概率,从而产生最后的检测区域。
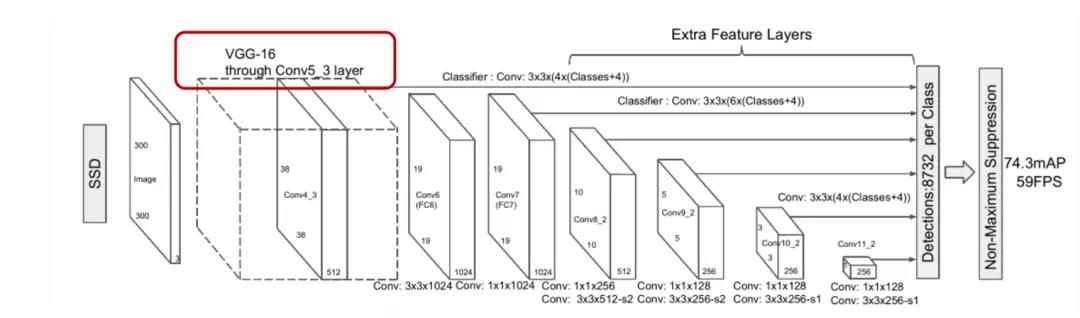
SSD算法中主干网络就是VGG,然后用了图像金字塔的原理进行了不同尺寸卷积核的特征提取。我用通过百度搜索的图片代入模型,发现最后的效果非常不错。

对于目标检测数据集,需要额外在图片上标注Bounding-Box的坐标,ImageNet也包含了这种大量标注的图片,大家可以尝试一下。
对于深度学习的简单介绍就到这里,除了CV,深度学习一些如LSTM、GRU、BERT等模型还能很好的解决机器翻译和语义识别的问题,也希望我们公司的NLP组能够来分享这方面的知识。
大数据、算法、算力
没有大数据的支持,沉寂多年的算法绝对派不上用场,但是没有大算力和好的大数据框架的支持,好的算法也无法充分发挥他们的威力。

比如我们公司深耕多年的大数据领域的组件框架Hadoop、Spark、Alluxio等,以及近年流行的容器相关的Docker、Kubernetes,它们通过大规模分布式并行计算以及大规模集群的算力调度,从而实现大数据的建模和分析。

硬件层面,GPU和TPU也为机器学习的算力提供支持,大大降低机器学习的运行时间,未来随着量子机器学习的发展,会有更多的算力涌现。
机器学习、大数据、大算力共同培育了我们这个时代的一个机遇。我觉得这个机遇有两个特点,第一个是无限的需求。
大数据时代的机遇
著名的统计学家Andrew Gelman曾说过:“样本从来都不是足够大的。如果 N 太大不足以进行足够精确的估计,你需要获得更多的数据。但当 N “足够大”,你可以开始通过划分数据研究更多的问题,例如在民意调查中,当你已经对全国的民意有了较好的估计,你可以开始分性别、地域、年龄进行更多的统计。N 从来都无法做到足够大,因为当它一旦大了,你总是可以开始研究下一个问题从而需要更多的数据。”
将这段话放在我们当前数据化程度越来越高的时代来看,我们会有无穷无尽的需求,当一个需求感觉解决了,但是随后积累的越来越细化的数据又会从这个需求中诞生更多的小需求。所以我们面临的场景其实是无限多,机会也是无限多的。
第二个特点是技术的高杠杆,只要你能够用机器学习解决一个场景的问题,相关解决方案能够快速推广应用其他类似应用中。比如CV四小龙商汤、云从、依图、旷视初期都是如此,这同样也是计算机行业的魅力。
除了技术的杠杆之外,国家从去年开始也一直大力发展科技,从进博会宣布开始短短半年就成功开启的科创板,到现在创业板的注册制、新三板的分层,都在帮助科技创新企业融资上市。这几天华为等企业又被美国制裁,国家势必要继续加码科技,这也是我们国内整个IT行业的机遇,特别是对于从事大数据以及人工智能等前沿核心技术的企业。
常见机器学习的三大任务
介绍完了机器学习的领域知识,现在我们来看今天重点的技术分享——AutoML。
前面通过KNN和手写数字集展示了一个机器学习项目的流程,我们一般将识别手写数字这样一个问题称为分类任务,因为结果是我们预先知道并且可枚举的,比如预测明天股票的涨跌,这就是一个二分类的任务。如果我们要预测明天股票的具体价格,这就是一个回归的任务了,因为股价会落在一个连续区间,不好枚举。


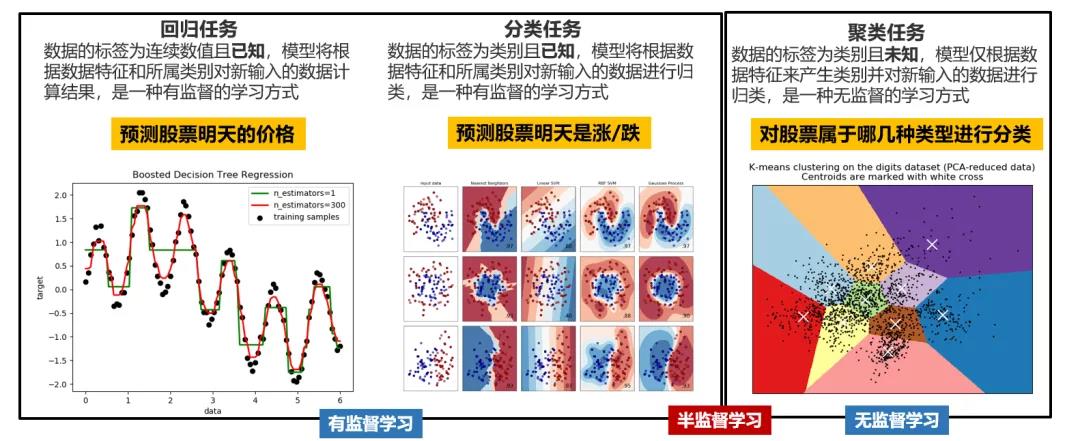
上面两个任务的开始前提就是我们已经准备了有标签的数据,通过模型预测的结果可以用已有的标签来评估模型的好坏,对于这种任务我们可以将其归为有监督的学习,因为其预测的结果是在我们的监督之下评估的。
除了回归、分类之外,我们还有聚类任务,比如我们事先不知道哪些股票具备类似的特征,我们就可以用聚类任务将其聚到一起归为一类。与回归分类不同的是,聚类任务事先没有标签,我们并不清楚哪些股票会被聚到一起,所以聚类任务也属于无监督学习。
在有监督和无监督学习间还存在一种半监督学习,这是现在非常流行的研究领域。因为我们现实生活中并不具备给所有数据打上标签的条件,比如我们不可能每秒每帧给闸机视频上的人脸画上Bounding-Box。而半监督学习的思想就是我们先人工打上一些标签,然后利用这些已有的占比很小的标签来建模。
机器学习的一般流程
明确了三大任务之后,我们来看机器学习的一般流程,理解完流程大家也就明白了为什么我们需要AutoML。

首先我们需要导入数据,然后选择一个任务,比如股票涨跌的分类任务。然后我们需要进行一定的特征工程,将数据的特征进行调整、量纲进行统一。
特征的调整情况很多,比如你对y=x^2这一场景建模,那你无论输入多少的x都是没有什么效果的,直到你多传入了一个x^2才能将模型拟合起来。
量纲的统一也很必要,比如你将一个国家人口的平均年龄和该国的货币发行量作为数据的特征,一个是几十为单位的数,一个是几万亿的数。如果将不经处理的数据直接建模,其效果肯定大打折扣,利用数据的缩放可以让这两个特征都放到相近的区间,比如0-1。
特征工程一般很依赖行业的知识和对数据的理解。利用特征工程对数据处理完毕之后,就需要你选择一个模型了,但是传统的机器学习模型多达几十个,每个模型看待世界的方式都不同,除非你同时是行业专家以及数据专家,否则你可能要花大量时间选出个模型。
选完模型后你还要去调整参数,比如之前KNN的K,但是效果更好的模型往往参数很多,没有统计学背景的人在调参上又会花费大量的时间。
经过了特征工程、模型选择和参数调整后,就要将其与结果进行对比了,这时我们可能会发现这套流程并不合适导致模型结果不好,又要反过来操作这一流程,整体耗时非常长。所以人们就想何不将其自动化呢,这就产生了我们AutoML的需求。
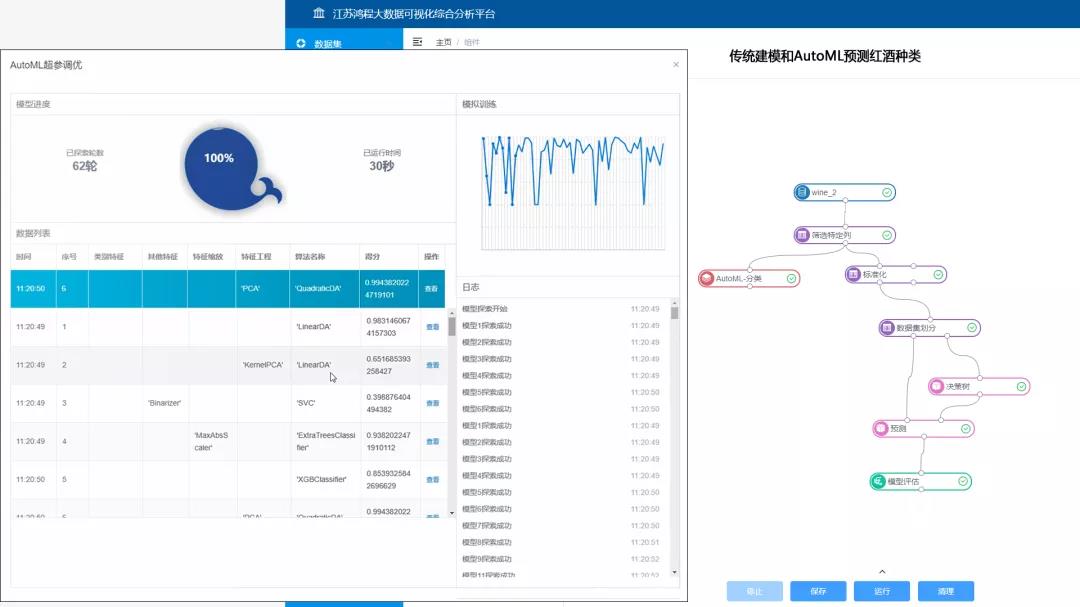
第一层AutoML:超参调优
我们对AutoML的需求其实是分层级的,第一层是对一个模型的超参数调优的需求。
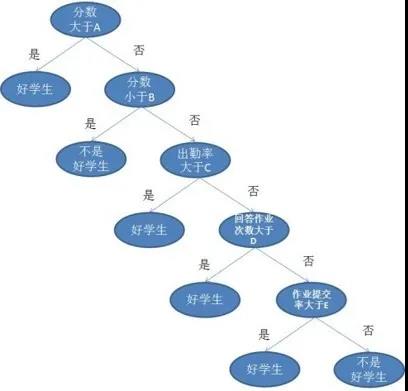
上图是一个决策树的建模过程,我们先通过一个人的分数来判断TA是不是好学生,然后又判断了出勤率、作业的互动情况、提交次数等。但是其实这一过程有很多可以调整的参数,比如为什么选择分数放在第一个,而不放作业提交率呢?还有为什么我们要判断这么多层呢?其实这些设定都是我们的超参数。
在sklearn中我们可以调整的超参数主要有下面5个,但是基于决策树的其他模型比如XGBoost等参数多达数十个,对于这种参数的调整就是很头疼的一个事情。
对于参数调优,我们一般有网格搜索、随机梯度下降和贝叶斯超参优化。
网格搜索顾名思义,就是比如有2个超参数都是1-10,那么两个参数两两组合就会有10^2种情况,如果有10个超参数就是10^10。这种参数调整方式就是会很准确,但是效率太低了。
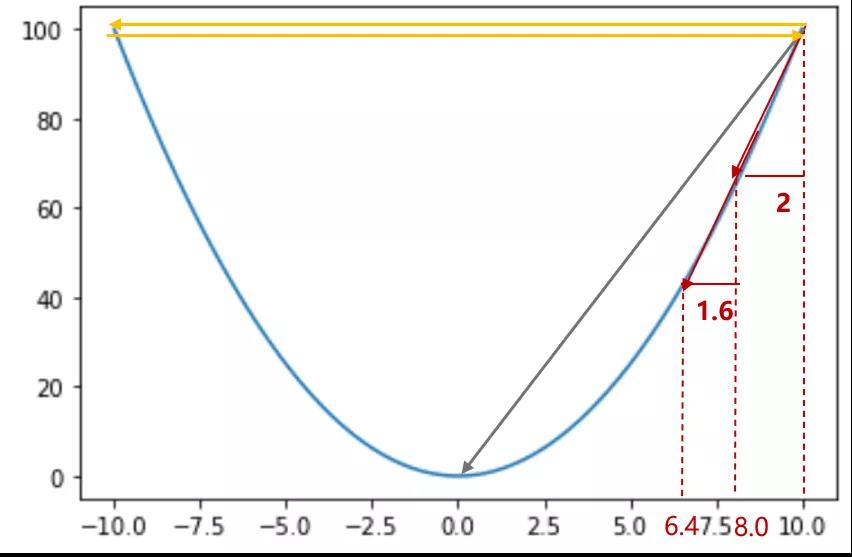
梯度下降则是模仿了我们过坐山车的原理,如上图所示,我们的目的是将模型的错误率调到最低。所以在坡度高的时候,我们发现动一点参数精度就会上升很多,那么我们下次就把这个参数多移动点,到了快逼近最优点的时候,我们就少移动一点作为精调。
这种调参方式效率很高,但是可能会陷入局部最优化,比如还没到最优点这个“大坑”,就在局部最优的“小坑”停了下来。
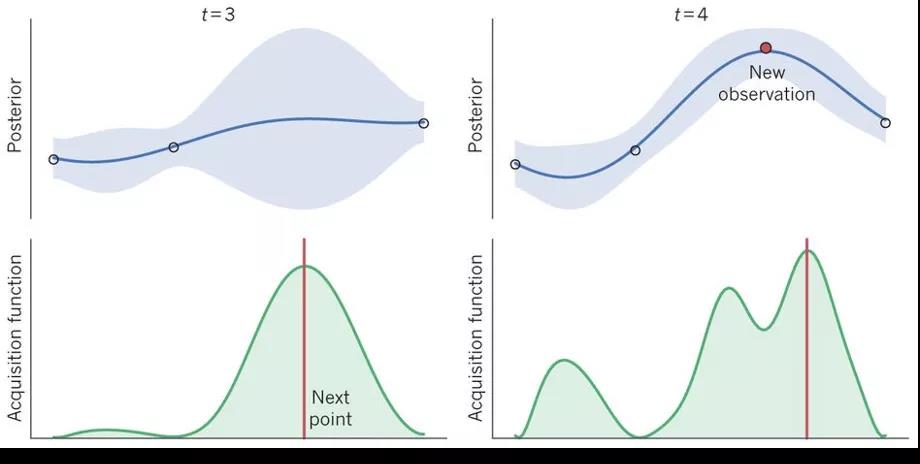
还有一种是现在业界流行的贝叶斯超参优化,它基于高斯过程贝叶斯线性回归,可以简单理解成图中每次选出几个点,然后取期望最大值作为下次要选的点,根据这些点连成的线作为我们预测的参数影响结果的曲线,即目标函数的概率模型。
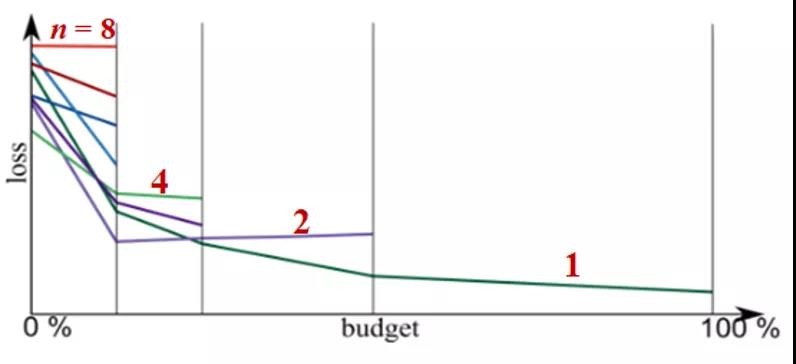
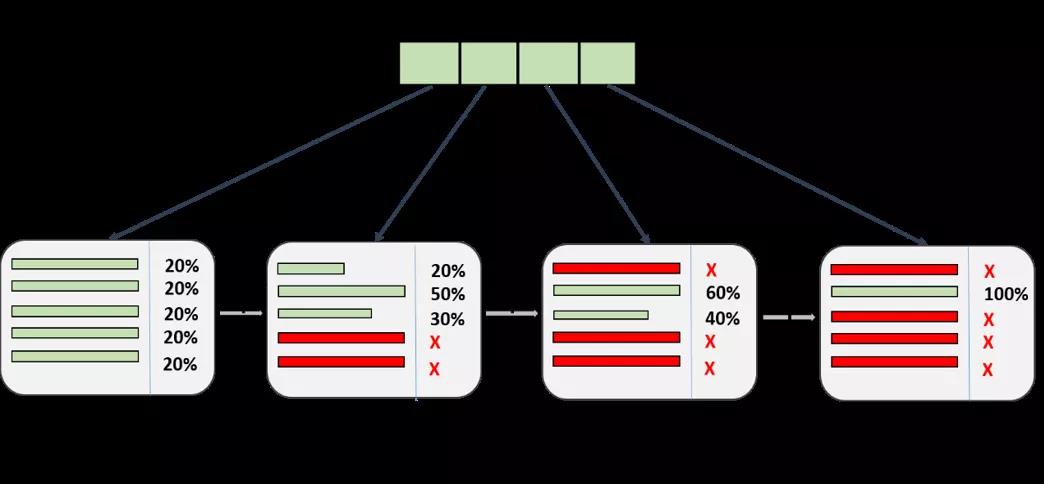
我们则是在贝叶斯超参优化的基础上加了一个HyperBand的资源限制,根据规定时间每轮进行一些超参数组合的淘汰,从而让更多的资源能够赋予给剩下结果更好的超参数组合,让它们有更多的时间进行精调。
第二层AutoML:模型选择和超参调优
AutoML的第二层需求是模型选择的同时进行超参调优。
这种需求需要利用到强化学习。多摇臂娃娃机问题是强化学习的经典问题,问题描述了这样一个场景:单身男子走入商场面对多个摇臂、但爪子松紧不同的娃娃机,男子并不知道娃娃机们抓到娃娃的概率分布是什么,所以为了选出能获得最大收益的那台娃娃机,男子需要有策略地快速试一试。
这种问题也是一个推荐算法的问题,比如大家去饭馆吃饭,面对同一道菜,我们有时候会觉得这个菜好吃一些 (概率=p),有时候这个菜难吃一些 (概率 = 1-p),但我们并不知道概率p是多少,只能通过多次观测进行统计。菜做的好吃时 (概率=p),客人一定会留下(reward=1);菜不好吃时(概率 = 1- p),客人一定会离开 (reward=0)。不考虑个人口味的差异,而实际上菜好吃不好吃只有客人才说的算,饭馆是事先不知道的。
那我们如何解决见人下菜的问题呢?
我们可以分为两个阶段进行:
①探索阶段 (Exploration):通过多次观测推断出一道菜做的好吃的概率 - 如果一道菜已经推荐了k遍(获取了k次反馈),我们就可以算出菜做的好吃的概率:
②利用阶段 (Exploitation):已知所有的菜做的好吃的概率,该如何推荐?- 如果每道菜都推荐了多遍,我们就可以计算出N道菜做的好吃的概率,那么我们就可以推荐好吃概率最大的那道菜。
其实探索和利用是强化学习经久不衰的问题:Exploration的代价是要不停的拿用户去试菜,影响客户的体验,但有助于更加准确的估计每道菜好吃的概率,Exploitation会基于目前的估计拿出“最好的”菜来服务客户,但目前的估计可能是不准的(因为试吃的人还不够多)
了解这个问题也能帮助我们理解生活中的一些现象。比如大家刷抖音或者头条新闻的时候经常会刷到自己感兴趣的东西,这就是强化学习在Exploitation利用了,但是偶尔也会有自己没有看过的领域,因为总有之前没有出现过的新内容,强化学习此时就是在Exploration探索了。
我们这里就用了见人下菜的强化学习方式,不同的是我们用了一种UCB得分的度量方式,在此基础上根据UCB得分分配不同的晋级概率和运行资源。
第三层AutoML:特征工程、模型选择和超参调优
这个需求解决之后,最终的需求来了:同时选择特征工程、模型选择和超参调优。
之前只是选择模型,所以用UCB一个得分就能描述菜的好坏了,但是这里的还要考虑到特征工程,这样就需要我们记录更多的状态,这里我们使用了Q-Learning这种强化学习算法。
为了演示这种强化学习算法的原理,让我们先来看一个动图。
在这个动图中,方块不断地移动,去获取那个圆球,如果获取到了就算胜利,反之如果落入了两个黑色方块的陷阱,就游戏结束。可以看到的是方块开始的时候很容易落入陷阱,但是之后却越走越顺畅,能够直接获取小球。
这是因为这个方块每次有上下左右4个动作,每步动作都会带来反馈,比如获得小球+1分,没有获得+0分,掉入陷阱-1分。Q-Learning会有一个记忆参数,能够帮助小球记得奖励和惩罚,从而帮助方块很顺利获得小球。
这和我们小时候学习一样,如果考试考砸了,爸妈就会抽你,从而让你加深痛苦的记忆,下次不会再避免落入陷阱。如果考试考的不错,你爸妈就会拿好吃的奖励你,然后考得就越来越好,但也会吃的越来越胖。
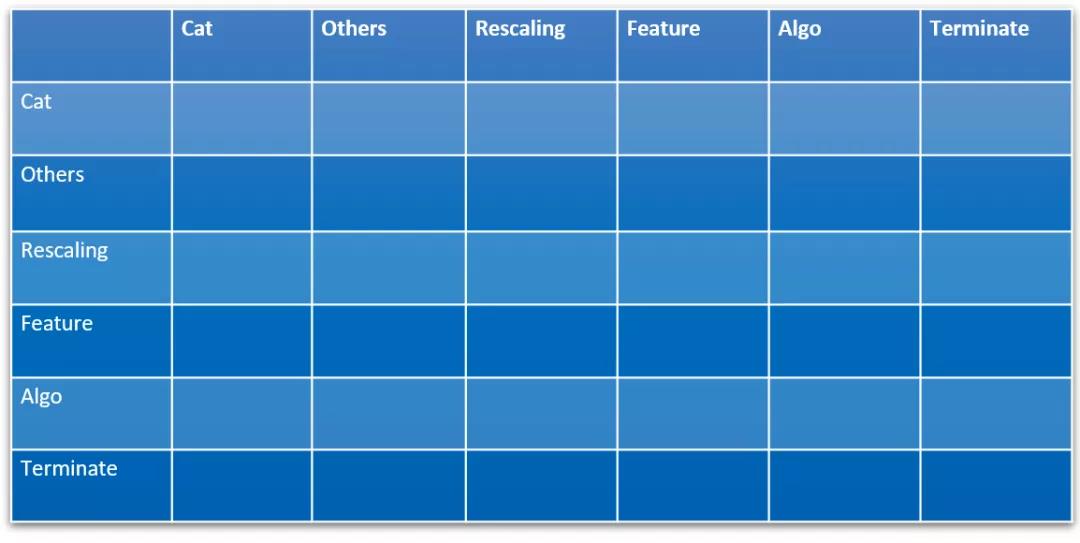
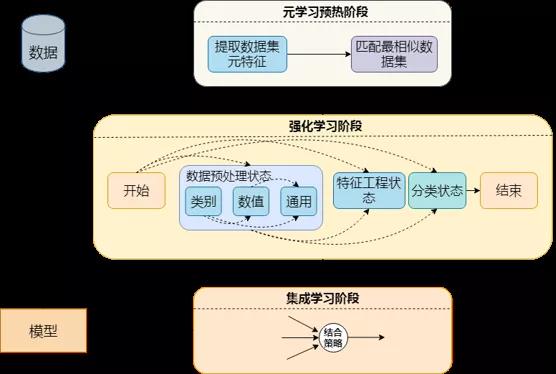
在我们的Q-Learning中会有一个这样的Q-Table去记录这个过程。比如图中我们会先进行类别、数值、通用的特征预处理,然后进行特征工程,再到算法选择,这是一个串行的过程,所以我们就可以设计一个这样6*6的Q-Table,列表示动作,行表示当前的状态。
AutoML的其他思想:元学习
在这个Q-Learning的基础上我们还做了其他的延伸。
比如大家看到那个成功获得小球的方块,如果程序重新执行,那么这个方块还是会重新探索一遍,重新构建它的Q-Table,但是这样效率太低了。所以我们自然想到用一种热启动的方式来加速训练。
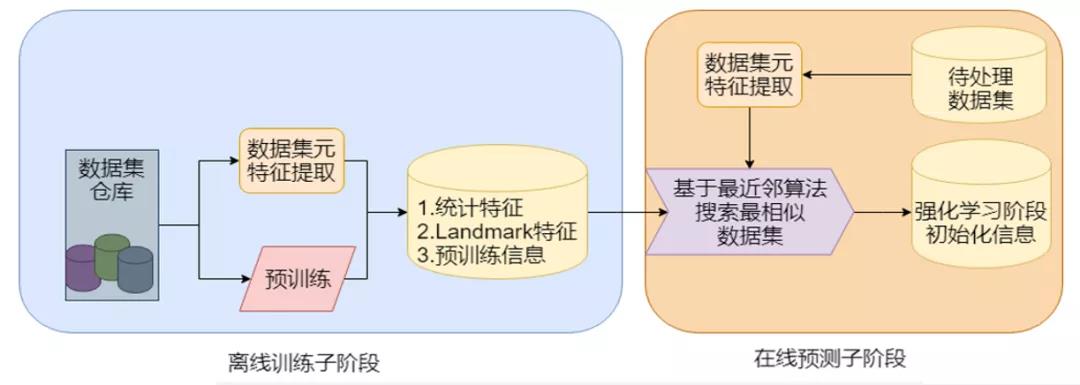
元学习(Meta-Learning)就能很好解决这个问题。它的原理是根据历史的一些数据集预先训练好,然后将其最终的Q-Table的参数存入本地仓库。之后有新的数据集需要训练的之前,先计算出这个数据集的元特征,比如这一列的标准差、偏度、峰度等等40个指标,然后根据这些指标从本地仓库找到最相近的数据集它的Q-Table,以此来加速新数据集的训练。
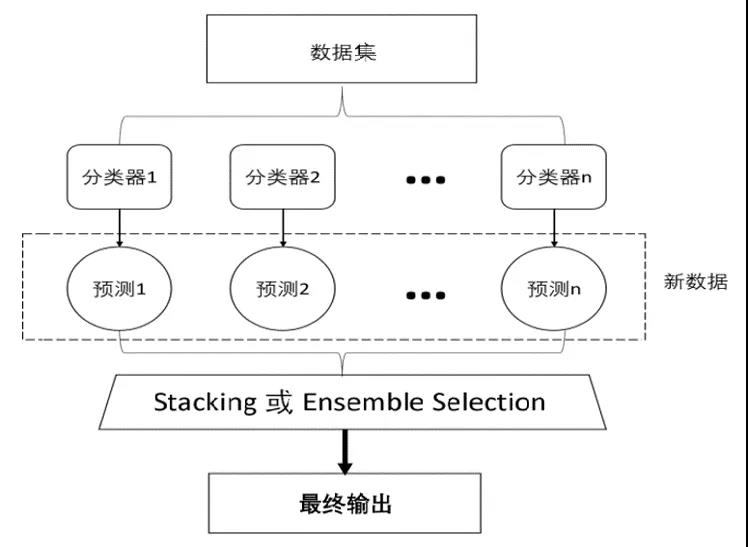
除了元学习外,我们还考虑了集成学习。在强化学习的训练过程中,会产生大量的模型,它们有的没有最佳模型得分那么高,但是有时候也不逊色多少,如果直接弃之不用还挺可惜。此时我们就可以利用集成学习,将最好的几个模型保留下来,进行Bagging投票,得到的结果往往更好。
最终我们的AutoML就形成了这一形态。先通过元学习进行热启动,然后进行强化学习,最终结果进行了集成学习。
AutoDL原理
除了传统的AutoML,我们还做了AutoDL的工作。
由于深度学习在图像识别、语言识别和机器翻译产生了巨大的成功,所以对网络架构工程师的需求也越来越多,而这又是耗时且容易出错的工作,所以自动化的神经网络架构搜索NAS应运而生。
和AutoML不同,AutoDL更多的只是搜索一个架构和组件。比如最简单的搜索空间是串行的线,但是复杂一点的要考虑到skip connections。
还有一些以block为结构的单元,借鉴了很多人工神经网络的复用结构。
考虑到搜索空间巨大,并且每次搜索出来去训练也要花大量的算力,所以NAS并不容易。
以Google提出的高效神经网络架构搜索算法ENAS为例,它克服了神经架构搜索算力成本巨大的缺陷,将算力成本减少1000倍以上,仅用一块英伟达GTX 1080Ti显卡,就能在16个小时之内完成架构搜索。
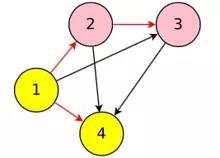
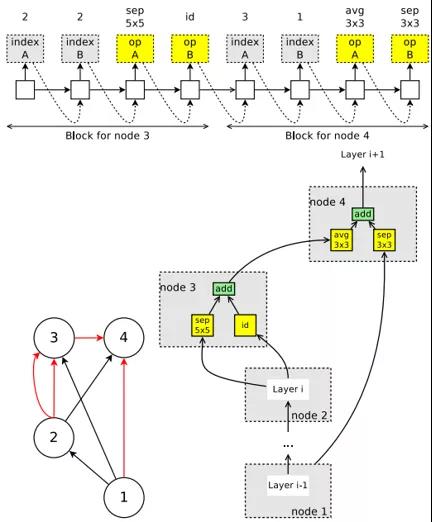
如上图所示,神经网络架构的搜索空间可以表示成有向无环图(DAG),一个神经网络架构可以表示成DAG的一个子图。红色的箭头是我们选择的一种连接方式。ENAS使用一个RNN(称为controller)决定每个节点的计算类型和选择激活哪些边。ENAS中使用节点数为12的搜索空间,计算类型为tanh,relu,identity,sigmoid四种激活函数,所以搜索空间有 约4^N*N!种约10^15种神经网络架构。
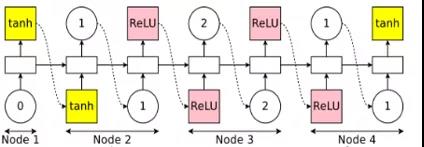
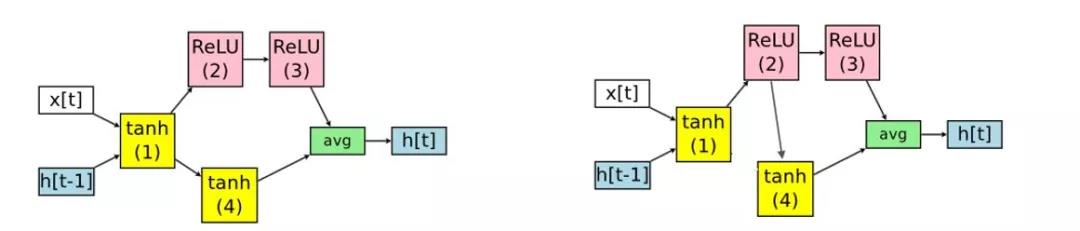
以节点数为4的搜索空间为例。即使是只有四个计算节点的RNN,也有多种有向无环图(DAG)的生成可能。我们选择了一组红色箭头组成的RNN,变成我们在下图中看到的结果。因为3和4是最后的端点,所以要进行avg这样的输出。
controller选择节点1的计算类型为tanh(节点1的前置节点是输入);选择节点2的前置节点为1,计算类型为ReLU;选择节点3的前置节点为2,计算类型为ReLU;选择节点4的前置节点为1,计算类型为tanh。
在NAS中,参数都是随机初始化,并在每个神经网络架构中从头开始训练的。但是在ENAS,这些参数是所有神经网络架构共享的。如果下一次controller得到的神经网络架构如下,它参数中很大部分都与上面神经网络架构相同。
之所以能够共享参数,是因为ENAS的思想是存在一个无所不能的超图HyperNet,我们每次利用控制器采样得到的只是这个超图的一个子集,所以每次其实我们都在去更新补足这个超图的参数,自然在结构相近的时候就能共享参数了。
上面演示的是RNN的训练过程,对于CNN其结构会更加复杂,但是原理都是基于此。
以上就是AutoML的技术内容。这里我们可以做一些对AutoML的展望。
首先是算力的提升带来AutoML的训练加速会加快AutoML的普及,把建模的过程交给计算机。
另一方面,数据化时代的不断深入,我们对数据的采集也会几何倍的上升,我们的应用场景会越来越丰富,AutoML的施展空间也很大。
最后,随着学界理论的不断增强,这些黑盒子也会慢慢揭开它们神秘的面纱。
我们的AutoML产品性能优越,连续多次在国际著名的AutoML大赛中以优异成绩获奖,在多种不同类型和特性的AutoML技术方面,均具有很强的技术实力,并获邀去澳大利亚、美国做技术报告。参赛队伍包括清华大学、北京大学、麻省理工大学等国内外知名高校以及微软、腾讯、阿里巴巴等科技巨头公司。
我们的产品自主原创,国际先进,核心技术已得到华为、360等企业认可,帮助华为和360大大的减少了建模的人力成本。该产品还荣获第五届中国“互联网+”大学生创新创业大赛全国金奖。
更多有关我们产品的介绍可以参考往期推送:
【产品介绍】PASA-AutoML——人工智能自动化建模工具平台
我们对AutoML的工作都已经产品化,可以以源码导包的形式,也可以和我们公司的大数据可视化建模分析平台结合在一起使用。
如上图所示,右侧是传统机器学习的流程,左侧是使用我们AutoML的界面,可以通过我们的AutoML将选出的最佳组合一键转成右边的流程。
欢迎对该产品有需求的朋友和我们联系。






AutoML的其他思想:集成学习




我们的AutoML产品