

2019-12-06
分享到以下文章转载自腾讯智能钛AI开发者
时间序列简单来讲是指一系列在时间轴上有序的数据,而时序预测是根据过去时间点的数值来预测将来时间点上的数值。现实中,时间序列预测除了在电信运营商中的网络质量分析、面向数据中心运营的日志分析、面向高价值设备的预测性维护等多有应用之外,还可用作异常检测的第一步,以帮助在实际值偏离预测值过多时触发警报。
传统的时序预测方法通常使用描述性的(统计)模型,来根据过去的数据对未来进行预测。这类方法通常需要对底层分布做一定的假设,并需要将时间序列分解为多个部分,如周期、趋势、噪声等。而新的机器学习方法对数据的假设更少、更灵活,比如神经网络模型——它们通常将时间序列预测视作序列建模问题,最近已成功应用于时间序列分析相关的问题(如[1]和[2]所示)。
然而,为时间序列预测构建机器学习应用是一项费力且对专业知识要求较高的工作。为提供易于使用的时间序列预测工具套件,我们将自动化机器学习(AutoML)应用于时间序列预测,并对特征生成、模型选择和超参数调优等流程进行了自动化。该工具套件基于Ray(面向高级AI应用的开源分布式框架,由UC Berkeley RISELab提供)搭建,是Analytics Zoo——由英特尔提供的统一数据分析和AI开源平台的一部分。
Ray 和 RayOnSpark
Ray提供了一种通用的集群计算框架,可满足新兴AI技术对系统性能的苛刻要求。例如,Tune是一个基于Ray构建的分布式可扩展超参数优化库,支持用户使用高效搜索算法在大型集群上轻松运行许多实验。
Analytics Zoo近期提供了对RayOnSpark的支持,允许用户基于Ray构建新的AI应用,并可以在现有大数据集群中直接运行,进而将其无缝集成到大数据处理和分析流水线中。我们将在后文介绍如何利用Ray Tune和RayOnSpark实施可扩展的AutoML框架和自动时间序列预测。
Analytics Zoo中的AutoML框架
下图描述了Analytics Zoo中的AutoML框架架构。
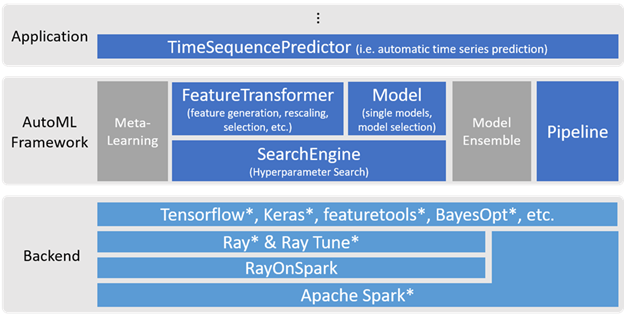
[1]Analytics Zoo中的AutoML框架架构
AutoML框架在特征工程和建模的组件中使用Ray Tune进行超参数搜索(运行在RayOnSpark上)。
在特征工程部分,搜索引擎从各种特征生成工具(如featuretools)自动生成的特征集中选择最佳特征子集。
在建模部分,搜索引擎可搜索各种超参数,如每层的节点数量、学习率等。我们使用流行的深度学习框架(如Tensorflow和Keras)来构建和训练模型,在必要时我们会将Apache Spark和Ray用于分布式执行。
AutoML框架目前包括四个基本组件,即FeatureTransformer、Model、SearchEngine和Pipeline。
·FeatureTransformer定义了特征工程流程,其通常包括一系列操作,如特征生成、特征缩放和特征选择。
·Model定义了模型(如神经网络)和使用的优化算法(如SGD、Adam等)。Model还可能包括模型/算法选择。
·SearchEngine负责搜索FeatureTransformer和Model的最佳超参数组合,控制实际的模型训练过程。
·Pipeline是一个集成了FeatureTransformer和Model的端到端的数据分析流水线。Pipeline 可轻松保存到文件中,方便后续加载重新使用。
AutoML框架的一般训练工作流程如下所示:
1、首先实例化FeatureTransformer和Model,SearchEngine随后进行实例化,并由 FeatureTransformer和Model及一些搜索预设(指定超参数搜索空间、奖励指标等)进行配置。
2、SearchEngine运行搜索程序。每次运行将生成多个试验,并使用Ray Tune将这些试验在集群中分布式运行。每个试验使用不同的超参数组合进行特征工程和模型训练流程,并返回目标指标。
3、在所有试验完成后,可根据目标指标检索出一组最佳的超参数,并得到训练好的模型。它们将用于创建最终的FeatureTransformer和Model,并用于构成Pipeline。Pipeline可被保存至文件中,以便通过后续加载用于推理和/或增量训练。
为时间序列预测训练TimeSequencePredictor
在训练TimeSequencePredictor之前,需要先初始化RayOnSpark(在集群上使用Spark本地模式或YARN模式),训练结束后可以停止RayOnSpark。
在成功初始化RayOnSpark后,可以训练时间序列预测流水线,具体细节如以下示例所示。首先用必要的参数初始化一个 TimeSequencePredictor对象,然后调用TimeSequencePredictor.fit,以分布式的方式对历史数据自动地进行机器学习训练,在训练结束后得到一个TimeSequencePipeline对象。

·TimeSequencePredictor的输入数据(train_df) 是包含一系列记录的 (Pandas) Dataframe,每条记录包含一个时间戳 (dt_col) 及与时间戳关联的数据点数值 (target_col),每条记录还可包含额外的输入特征列表 (extra_feature_col);TimeSequencePredictor训练完成之后得到TimeSequencePipeline,用于预测未来时步的相应target_col。
·recipe参数包含TimeSequencePredictor所需的参数,用于在训练时指定搜索空间、停止条件和样本数量(即搜索空间中生成的样本数量)。目前可用的recipe包括SmokeRecipe、RandomRecipe、GridRandomRecipe和BayesRecipe。
可以将训练结束时获得的TimeSequencePipeline(已包含最佳超参数配置和AutoML框架返回的训练好的模型)保存至文件中,并在后续对其进行加载,用于评估、预测或增量训练,具体细节如下所示。

如需查看更复杂的时间序列AutoML示例,可以参考 https://github.com/intel-analytics/analytics-zoo/blob/automl/apps/automl/nyc_taxi_dataset.ipynb 的用例,它使用了纽约市的历史出租车乘客量预测未来需求(类似于[2]中的案例)。下图使用AutoML展示了下一个时步的预计出租车乘客量。
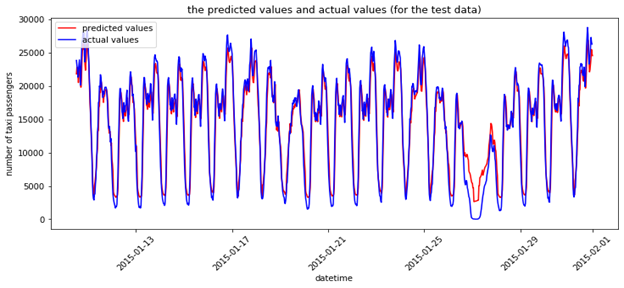
[2]预测下一个时步的纽约市出租车乘客
参考资料:
[1] Guokun Lai、Wei-Cheng Chang、Yiming Yang、Hanxiao Liu,“使用深度神经网络对长期和短期时序模式进行建模”(https://arxiv.org/abs/1703.07015)。
[2] Nikolay Laptev、SlawekSmyl、Santhosh Shanmugam,“优步使用递归神经网络设计极端事件预测功能”(https://eng.uber.com/neural-networks/)。


