

2019-11-11
分享到本文转载自联邦学习原创
联邦学习概念
联邦学习(Federated Learning)是一种新兴的人工智能基础技术,在 2016 年由谷歌最先提出,原本用于解决安卓手机终端用户在本地更新模型的问题,其设计目标是在保障大数据交换时的信息安全、保护终端数据和个人数据隐私、保证合法合规的前提下,在多参与方或多计算结点之间开展高效率的机器学习。
联邦学习在使数据保持本地化的同时,可在远程设备或孤立的数据中心(例如手机或医院)上训练统计模型。但在异构网络和潜在的大规模网络中进行训练无疑会带来新的挑战。
一、联邦学习的发展
移动电话、可穿戴设备和自动驾驶汽车仅仅是产生大量数据的现代分布式网络中的一部分。由于这些设备计算能力的不断提高,再加上对传输信息隐私安全问题的担忧,因此在本地存储数据并将网络计算推向边缘的方式变得越来越有吸引力。

联邦学习的应用实例
图源:Federated Learning: Challenges, Methods, and Future Directions
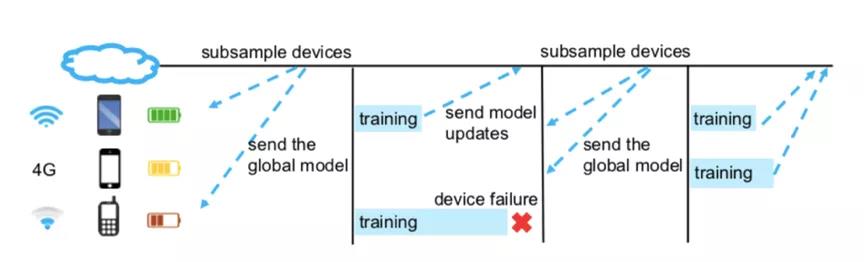
图中是联邦学习的一个应用示例,主要用于手机上的下一词预测任务。为了保护文本数据的隐私安全,减少网络压力,我们寻求以分布式方式训练预测变量。整个过程中远程设备会定期与中央服务器通信以学习全局模型。 在每个通信回合中,选定的电话子集会对它们不完全相同的用户数据进行本地训练,然后将这些本地更新发送到服务器。更新合并后,服务器会将新的全局模型发送回另一个设备子集。迭代训练的过程将在整个网络上持续进行,直到达到收敛或满足某些停止条件为止。
联邦学习技术发展至今,在支持隐私保护的应用程序中发挥着关键作用。潜在的应用示例包括:
1、智能手机:联邦学习具有在不降低用户体验和保护用户隐私安全的情况下在智能电话上启用预测功能的潜力。通过学习大量手机中的用户行为,训练模型可以为诸如下一词预测、面部检测和语音识别之类的应用提供技术支持。
2、医院组织:医院是包含大量患者数据以进行预测性医疗的组织,但是医院对于数据隐私安全的要求极为严格,联邦学习可以减轻网络的压力并支持各种医院组织之间的私有学习。例如预测心脏病发作的风险、癌症风险等等。
3、物联网:可穿戴设备、自动驾驶汽车或智能家居之类的现代物联网网络包含众多传感器,它们能够实时收集、响应并适应传入的数据。例如:自动驾驶汽车需要交通状况、建筑位置和行人行为的最新模型才能安全运行。但由于数据的私有性以及设备连接的有限性,想要构建汇总模型是非常困难的。联邦学习可以在保护用户隐私的前提下训练联合模型,以有效适应这些物联网系统的变化。
二、联邦学习的挑战
挑战1:通信成本高
通信成本是联邦网络中的一个关键瓶颈。联邦网络由大量设备组成,因此网络中的通信速度比本地计算速度慢了许多个数量级。为了降低通信成本有必要开发一种高效通信的方法,在训练过程中迭代发送模型更新数据,而非通过网络发送整个数据集。
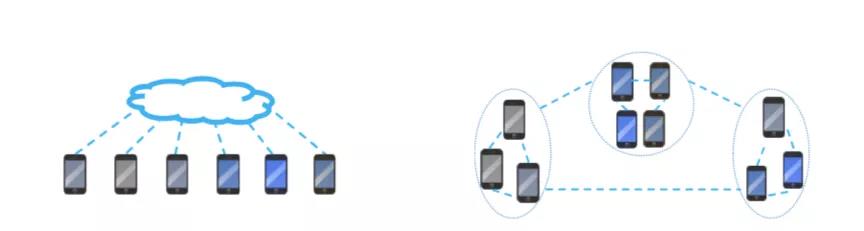
集中式拓扑与分散式拓扑
图源:Federated Learning: Challenges, Methods, and Future Directions
我们假设一个星型网络(左),其中服务器与所有远程设备连接,当与服务器的通信成为瓶颈时,分散式拓扑(右)是一种潜在的选择。
为了在这种情况下进一步减少通信,我们需要:
(1)减少通信回合的总数
(2)减小每个回合中已发送消息的大小
挑战2:系统异质性
联邦学习的系统异质性
图源:Federated Learning: Challenges, Methods, and Future Directions
联邦网络中每个设备的存储,计算和通信功能可能会因硬件(CPU,内存),网络连接性(3G,4G,5G,WiFi)和电源(电池电量)的变化而有所不同。
挑战3:统计异质性
设备经常以不完全相同的分布方式在整个网络上生成和收集数据,例如,移动电话用户在下一个单词预测任务的上下文中使用了多种语言,此外跨设备的数据点的数量可能存在很大差异。这种数据生成方式违反了分布式优化中常用的独立同分布假设,增加了建模、分析和评估的复杂性。
挑战4:隐私问题
联邦学习通过共享模型更新(梯度信息、损失信息等)而非原始数据来保护每个设备上的本地数据。但是在整个训练过程中,模型更新仍然可以向第三方或中央服务器泄露敏感信息。尽管目前有使用安全多方计算或差分隐私等方法来增强联邦学习的隐私保护力度,但是这些方法通常以降低模型性能或系统效率为代价。
三、联邦学习的未来
针对联邦学习技术发展道路上的瓶颈问题,我们这里简要的概述一些有前途的研究方向。
1、组合通信约简算法
目前联邦学习中有三种常见的通信技术:(1)本地更新方法(2)模型压缩技术(3)分散训练技术,如何将这些技术相互结合以进一步提高性能是很重要的。例如,模型压缩技术可以与基于重要性的更新技术相结合。这种组合能够显著减少从移动设备发送到服务器模型更新的大小。但是,目前需要进一步评估这种组合技术的准确性与通信开销之间的权衡。
2、量化统计异质性的新工具
移动设备通常通过网络以nonIID方式生成和收集数据。此外,移动设备之间的数据样本数量可能有很大差异。为了提高算法的收敛性,需要对数据的统计异质性进行量化。最近的一些研究已经开发出通过诸如局部差异等度量来量化统计异质性的工具。然而,在训练开始之前,很难通过联合网络计算这些指标。这些指标的重要性激发了未来的发展方向,比如开发高效算法来快速确定联合网络的异构程度。
3、数据隐私挑战解决方案
针对数据隐私挑战,可以引入了SMC协议来保护单个模型更新。中央服务器无法看到任何本地更新,但仍可以在每个回合中观察到确切的汇总结果。SMC是一种无损方法,可以保留原始准确性并保障数据隐私安全。但是该方法会导致相当大的额外通信成本。
4、联邦学习的应用
由于联邦学习具有保障数据隐私的优点,在医疗、金融、交通系统等诸多应用中发挥着越来越重要的作用。目前对联邦学习应用的研究多集中在学习模型的联合训练上,忽略了学习模型的实现问题。对于今后关于联邦学习应用的研究,有必要在调查中考虑上述问题,即通讯成本、资源分配、隐私安全,以确保一个联邦学习系统是可行的和可扩展的。
参考资料:
Federated Learning: Challenges, Methods, and Future Directions


