

2019-08-02
分享到朱光辉、王千、唐颀伟
本篇将分享南京大学PASA大数据实验室与江苏鸿程大数据研究院分布式并行计算研究组最近在大规模数据库函数依赖发现算法方面的研究工作。
该工作的论文发表在分布式并行计算领域顶级期刊IEEE Transactions on Parallel and Distributed Systems (TPDS, SCI期刊)上,论文题目为:Efficient and Scalable Functional Dependency Discovery on Distributed Data-Parallel Platforms。论文可以从IEEE论文数据库中获取。
论文引用:
G. Zhu, Q. Wang, Q. Tang, R. Gu, C. Yuan and Y. Huang, "Efficient and Scalable Functional Dependency Discovery on Distributed Data-Parallel Platforms," in IEEE Transactions on Parallel and Distributed Systems. doi: 10.1109/TPDS.2019.2925014
1、 问题背景
函数依赖(Functional Dependency, FD)指的是关系数据库中属性之间的依赖关系。假设X代表关系表中某一属性子集,A代表某一属性。如果属性子集X的取值能够唯一地确定属性A的值,那么函数依赖FD: X->A成立,X称为FD的左部,A称为FD的右部。举个例子,在地址数据表中,可以根据城市和街道确定邮政编码,也就是说(城市,街道)->(邮编)。函数依赖是关系型数据库中最常见的约束条件,并在数据库分析与设计、数据库查询优化、关系模式规范化、数据集成及数据清洗等领域有着广泛的应用。但是,对于给定数据集,其包含的FD通常是未知的。因此,需要研究高效的FD发现算法从给定的关系表中挖掘出所有的FD。
随着互联网等信息技术的快速发展,各行各业已步入大数据时代。在大规模数据场景下,典型的单机FD发现算法,如TANE、FUN、DFD、Dep-Miner、FastFDs、FDEP和HyFD等[1],存在着计算效率低、计算时间长以及内存开销大等问题。因此,这些单机算法可扩展性较差,无法高效地处理大规模数据。以目前最好的单机FD发现算法HyFD[2]为例。图1显示了其在不同数据规模下的性能。当数据集行数和列数增加时,由于巨大的内存开销和时间开销,HyFD已变得不可用。
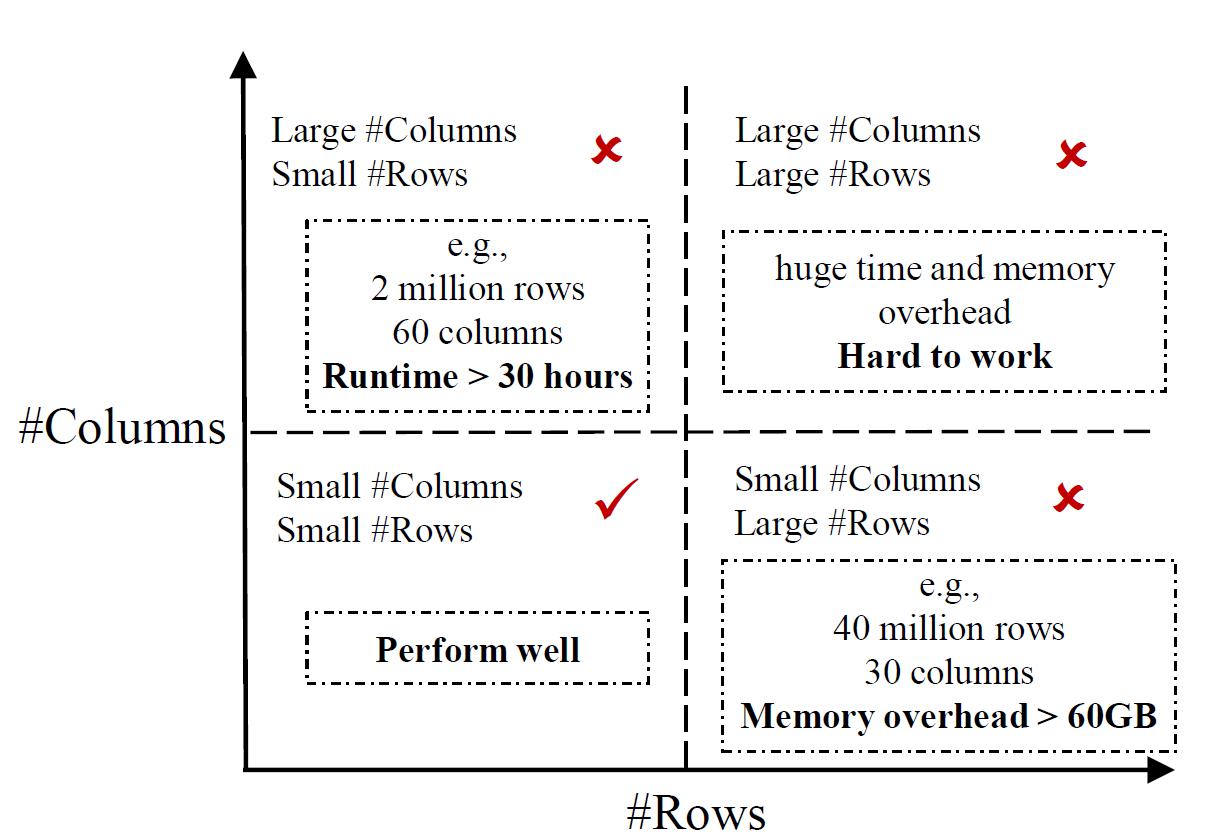
图1 目前最好的单机算法HyFD在不同数据规模下的性能
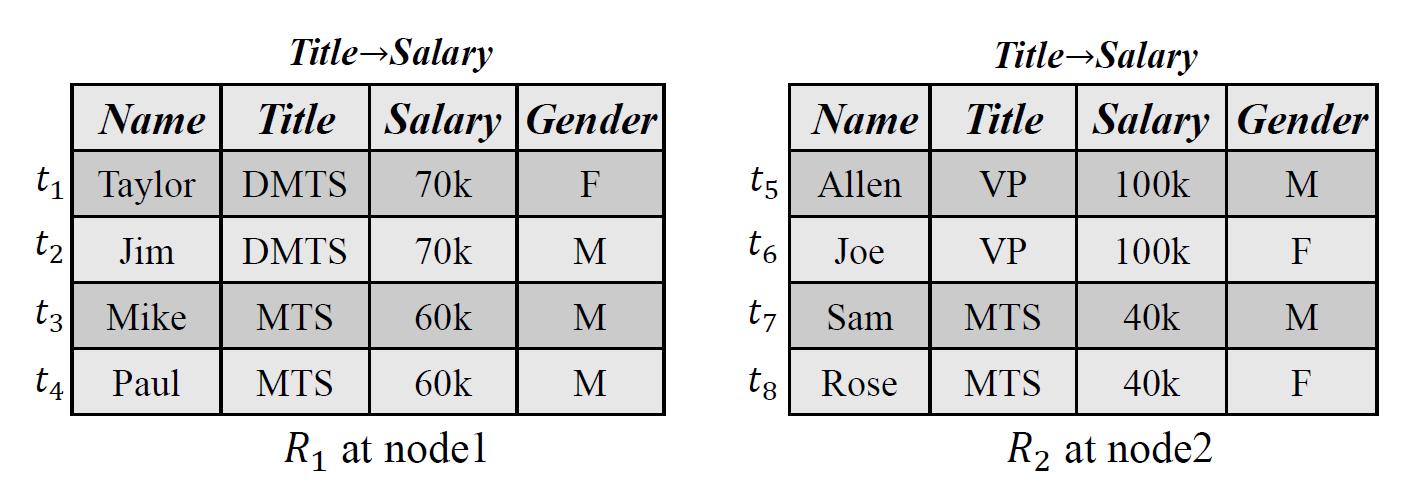
近年来,以MapReduce、Spark为代表的并行计算框架已经成为大数据处理的主流技术。这些并行计算框架采用的是数据并行计算方式,其将数据集分布式存储在多个节点上,然后在多个数据节点上并行执行计算。然而,这种传统的数据并行计算模式对于大规模函数依赖发现并不适用,无法保证函数依赖发现的正确性。也就是说,在某个数据分区上成立的函数依赖在整个数据集上可能并不成立。以图2为例,在节点1和节点2中,我们可以分别得到Title->Salary。但是,对于整个数据表而言,Title->Salary并不成立,因为t3[Title] = t7[Title],t3[Salary] ≠t7[Salary]。
为了解决上述问题和挑战,本文在保证函数依赖发现正确性的前提下,研究实现了一种高效可扩展的大规模分布式函数依赖发现算法SmartFD,其核心技术点如下:
1) 采用基于数据重分布的方法保证分布式函数依赖发现的正确性。给定一属性A,通过数据重分布,将在属性A上具有相同值的记录发送到同一数据分区。左部包含属性A的函数依赖如果在所有的数据分区上都成立,那么它也全局成立。因此,所有左部包含属性A的函数依赖可以被正确地发现。同理,通过依次处理所有的属性,最终正确地发现所有的函数依赖。
2) 为了实现负载均衡和提升集群资源利用率,研究提出了基于属性排序的分布式函数依赖发现算法框架。根据倾斜度和基数对属性进行排序,优先逐个处理“好”的属性(即倾斜度较低、基数较大)。
3) 研究设计了高效分布式的AFDD(Attribute-centric Functional Dependency Discovery)算法发现所有左部包含给定属性的函数依赖。AFDD算法包含三个主要步骤:数据重分布、基于FEEA(Fast Sampling and Early Aggregation)机制的分布式采样和基于索引的分布式验证。
4) 为了提升函数依赖的整体计算效率,研究设计了统一的基于时间的效率度量指标,并基于此提出了一种在分布式采样和分布式验证之间能够自适应切换的策略。
5) 通过前几轮AFDD算法,大部分函数依赖都可以被发现。为了进一步提升计算并发度和资源利用率,我们研究设计了Batch AFDD算法同时处理后面“差”的属性(即倾斜度较大、基数较低)。
我们基于Spark并行计算平台设计实现了大规模分布式FD发现算法SmartFD,并将其与当前最优的单机算法HyFD[2]和分布式并行算法HFDD[3]进行了性能对比。实验结果表明,SmartFD相对于目前单机最优算法HyFD可达到3.2到44.9倍的加速;相对于并行化算法HFDD可达到2.5到455.7倍的加速。在较大规模的数据集上,SmartFD相对于HyFD算法取得了超线性的加速比。且随着数据集规模的增大,HyFD和HFDD算法已无法在设定的时间和内存限制内运行出结果,SmartFD算法仍能够快速地进行FD发现,具有良好的数据可扩展性。同时,SmartFD能够实现近线性的节点可扩展性。
2、SmartFD总体框架
为了保证分布式函数依赖发现的正确性,需要依次处理每个属性。针对给定属性A,通过数据重分布,发现左部包含A的所有函数依赖。观察发现,通过处理前k个属性,能够发现大部分函数依赖。例如,对于包含10个属性的关系表,通过处理前4个属性,我们可以发现90%的函数依赖。因此,在整个函数依赖发现过程中,大部分的计算开销集中在处理前k个属性中。为了提升分布式计算的效率,倾斜度低、基数大的属性应该被优先处理。图3展示了SmartFD的总体框架,其分为两个阶段:数据预处理阶段和FD发现阶段。
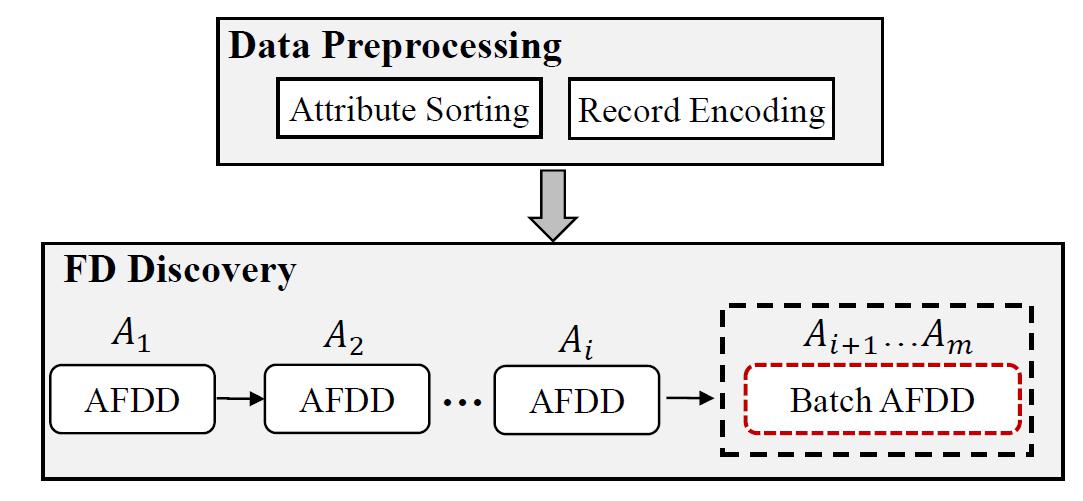
图3 SmartFD整体框架
在数据预处理阶段,我们提出了一种综合考虑属性倾斜度、基数以及基数方差的属性排序方法。另外,为了降低数据重分布时的网络通信开销,我们进一步对数据集记录进行字典编码。在FD发现阶段,我们提出了高效的AFDD算法用来发现左部包含给定属性的所有函数依赖。其中倾斜度低、基数大的属性被优先处理。为了提升集群计算资源的利用率,我们利用Batch AFDD算法同时处理剩下所有“较差”的属性。接下来,我们重点介绍SmartFD的核心:AFDD算法。
3、 AFDD算法
如图4所示,AFDD算法主要包含三个步骤:数据重分布、分布式采样和分布式验证。数据重分布的目的是保证函数依赖发现的正确性。分布式采样和分布式验证包含多轮。在每一轮分布式采样和分布式验证中,均可以根据不成立的函数依赖对候选函数依赖空间进行剪枝。另外,根据执行效率的不同,分布式采样和分布式验证可以自适应切换。
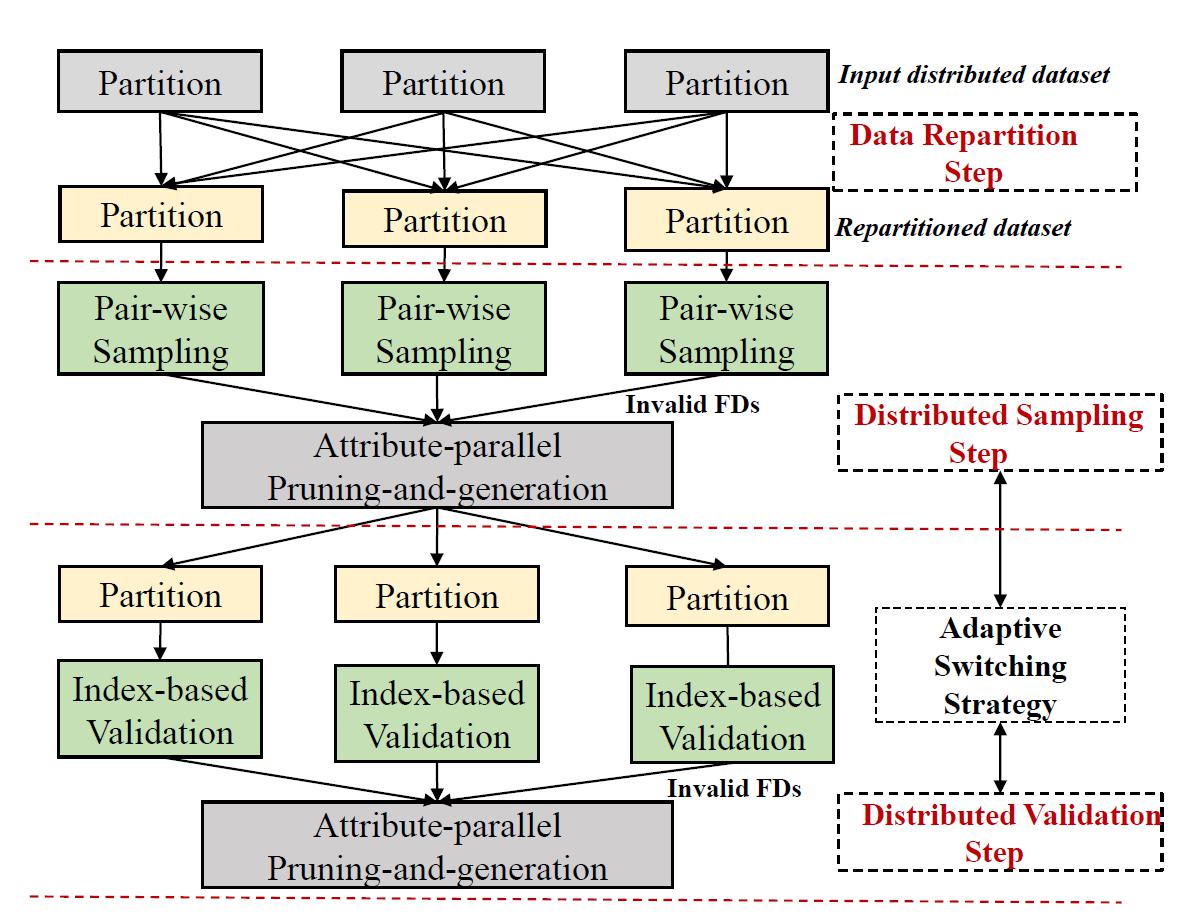
图4 AFDD算法整体流程
3.1 基于FSEA机制的分布式采样
分布式采样的目的是将不成立的函数依赖尽可能早的过滤掉,从而降低候选函数依赖的搜索空间。通过采样记录对和比较记录对中的记录,我们可以快速发现一些不成立的函数依赖。值得注意的是,只有采样至少有一个属性取值相同的记录对,才有可能发现潜在的不成立的函数依赖。
图5展示了基于Spark的分布式采样流程。数据是分布式存储的,在分布式采样过程中,每个数据分区的采样过程是并行执行的。因此,分布式采样将会导致每个分区采样时间不均衡、分区之间采样数据冗余等问题。为了尽量避免采样数据冗余和提升全局采样效率,我们提出了一种快采样(Fast Sampling)、早聚合(Early Aggregation)的分布式采样机制。每个数据分区均采用同样的采样窗口,保证每个分区的采样时间开销是均衡的。同时,每个分区的采样结果(即非法函数依赖)尽可能早地发送至主控节点,避免采样数据冗余。另外,通过采样得到的非法函数依赖,我们可以对候选函数依赖空间进行剪枝。从候选函数依赖空间中,移除掉不成立的函数依赖并生成新的候选函数依赖。进一步,主控节点通过计算全局采样效率,决定是否执行下一轮分布式采样还是跳转至分布式函数依赖验证。

图5 基于Spark的分布式采样
3.2 基于索引的分布式验证
通过分布式采样,大部分候选函数依赖可以被移除。对于未被移除的候选函数依赖,我们需要进一步在每个数据分区并行验证。如果候选函数依赖在每个数据分区上均成立,那么它也在全部数据集上成立。由于AFDD算法是用来发现左部包含特定属性的函数依赖,因此,分布式验证只需要在候选函数依赖空间中逐层验证左部包含特定属性的函数依赖。函数依赖验证过程将会产生大量的中间数据,内存开销巨大。为了降低内存开销,我们研究提出了一种基于索引的函数依赖验证方法。该方法为每条数据记录构建轻量级索引。索引主要由记录ID和待验证候选函数依赖左部值的哈希编码构成。通过直接比较索引验证候选函数依赖是否成立。图6展示了基于索引的函数依赖验证示例。待验证的候选函数依赖是A1A2->A3和A1A2->A4。
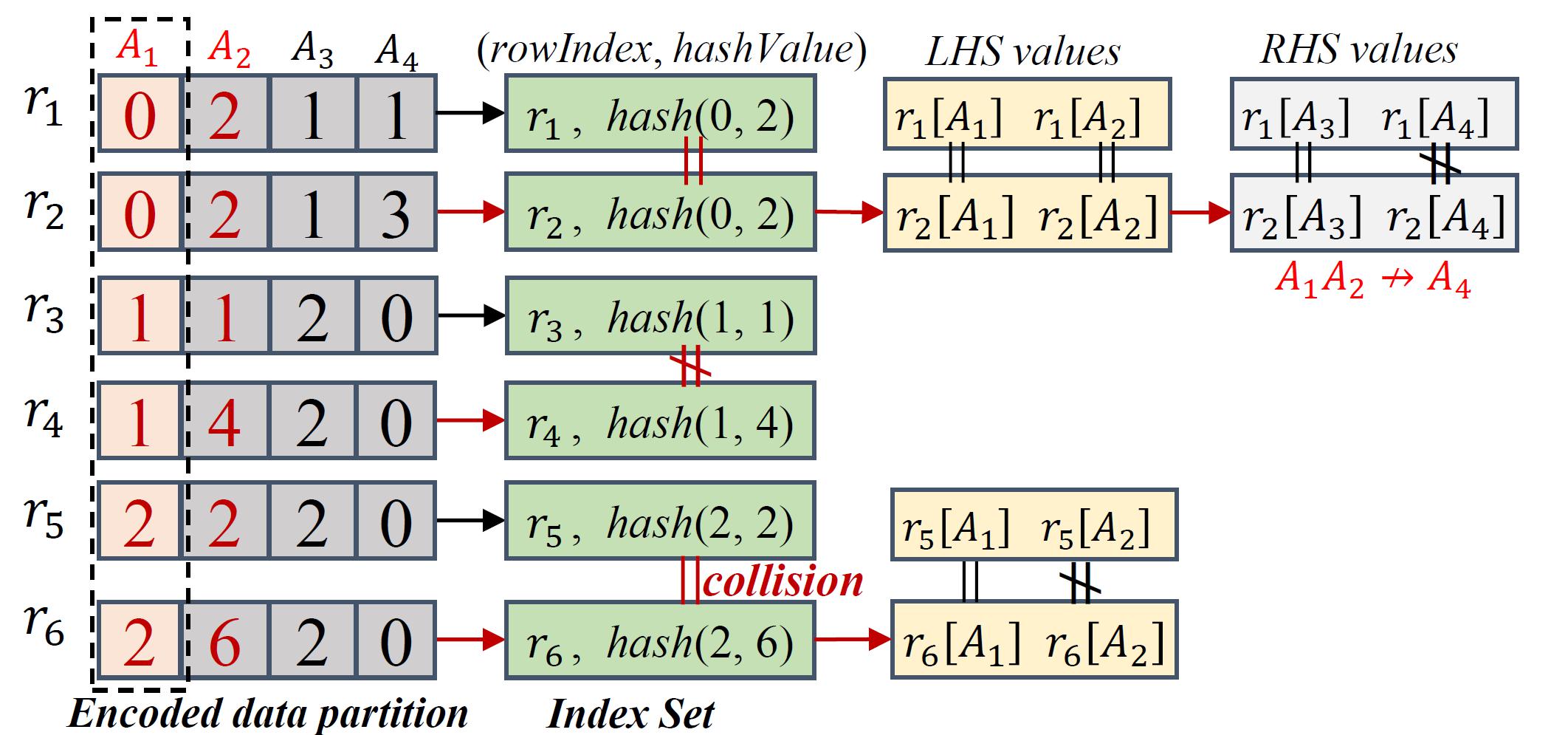
图6 基于索引的函数依赖验证(A1A2->A3A4)
3.3 自适应的切换策略
为了进一步提升AFDD算法的整体计算效率,我们提出了在分布式采样和分布式验证之间自适应切换的策略。其中,分布式采样和分布式验证均采用统一的基于时间的效率度量指标。分布式采样效率Es代表单位时间内从候选函数依赖空间中剪枝的函数依赖数量。分布式验证效率Ev代表单位时间内验证的函数依赖数量。根据Es和Ev,我们可以从运行时间开销角度决定哪个过程效率更高。另外,为了确定分布式采样和分布式验证的执行顺序,我们采用分布式探测的方法估计分布式验证的效率和失败率。如果失败率超过设定阈值,执行分布式采样。当分布式采样的效率低于分布式验证效率时,跳出分布式采样,执行分布式验证。如果失败率低于设计阈值,则直接执行分布式验证。
4、实验评估
我们在包含1个主节点和10个计算节点的集群中对SmartFD算法进行性能评估。本节摘录部分实验结果。SmartFD基于Spark平台实现,采用HDFS作为分布式数据存储。实验采用函数依赖算法性能评估中两个广为使用的数据集: ncvoter公众投票数据集和airline航空准点信息数据集。为了表达方便,我们用ncvoter-1m*20表示包含1百万行和20列的ncvoter数据集。
4.1 与目前最好单机FD发现算法的性能比较
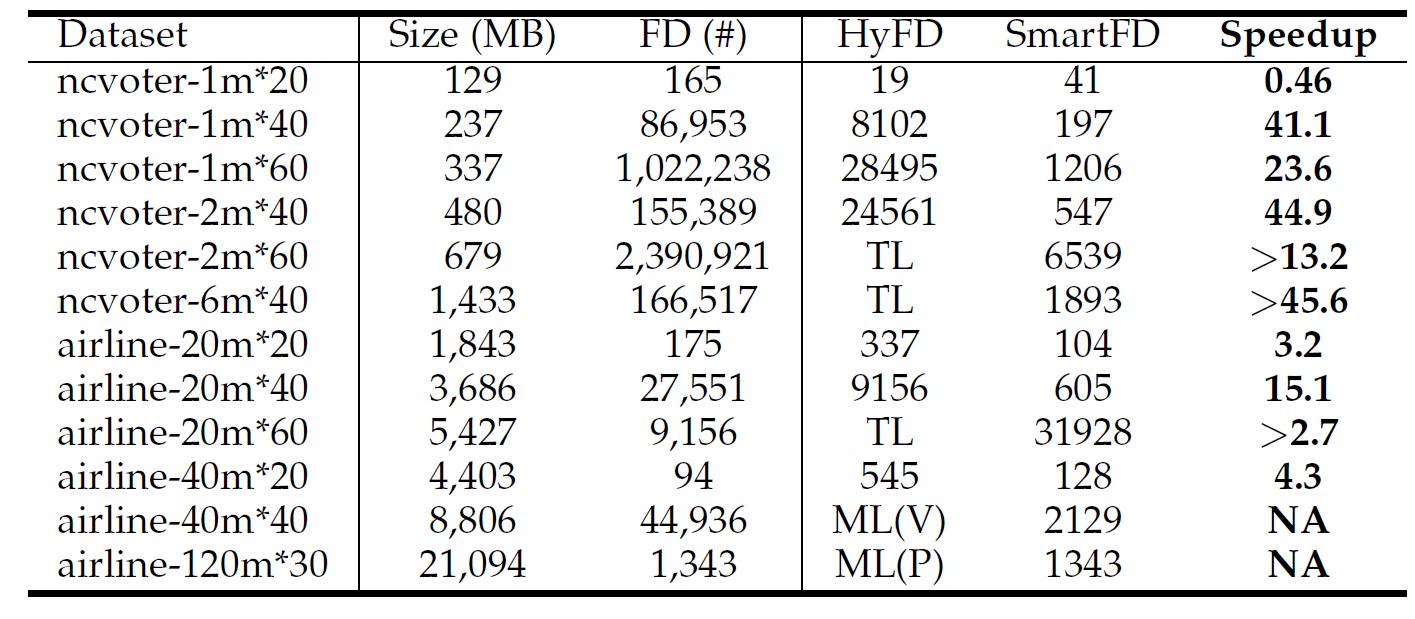
目前最好的单机FD发现算法是HyFD[2]。表1显示了SmartFD与HyFD的性能对比结果。从表1我们可以看出SmartFD能够实现3.2到44.9倍的加速比。随着数据集规模的不断增大,SmartFD依然具有良好的性能,数据可扩展性较高。与此同时,由于时间开销和内存开销较大,HyFD算法不能在规定的时间和内存限制内处理大规模数据。
表1 SmartFD与HyFD性能对比(时间:秒,TL: 运行时间超过24小时限制,ML: 内存开销超过60GB限制,V: FD验证阶段,P: 数据预处理阶段)
4.2 与已有分布式FD发现算法的性能比较
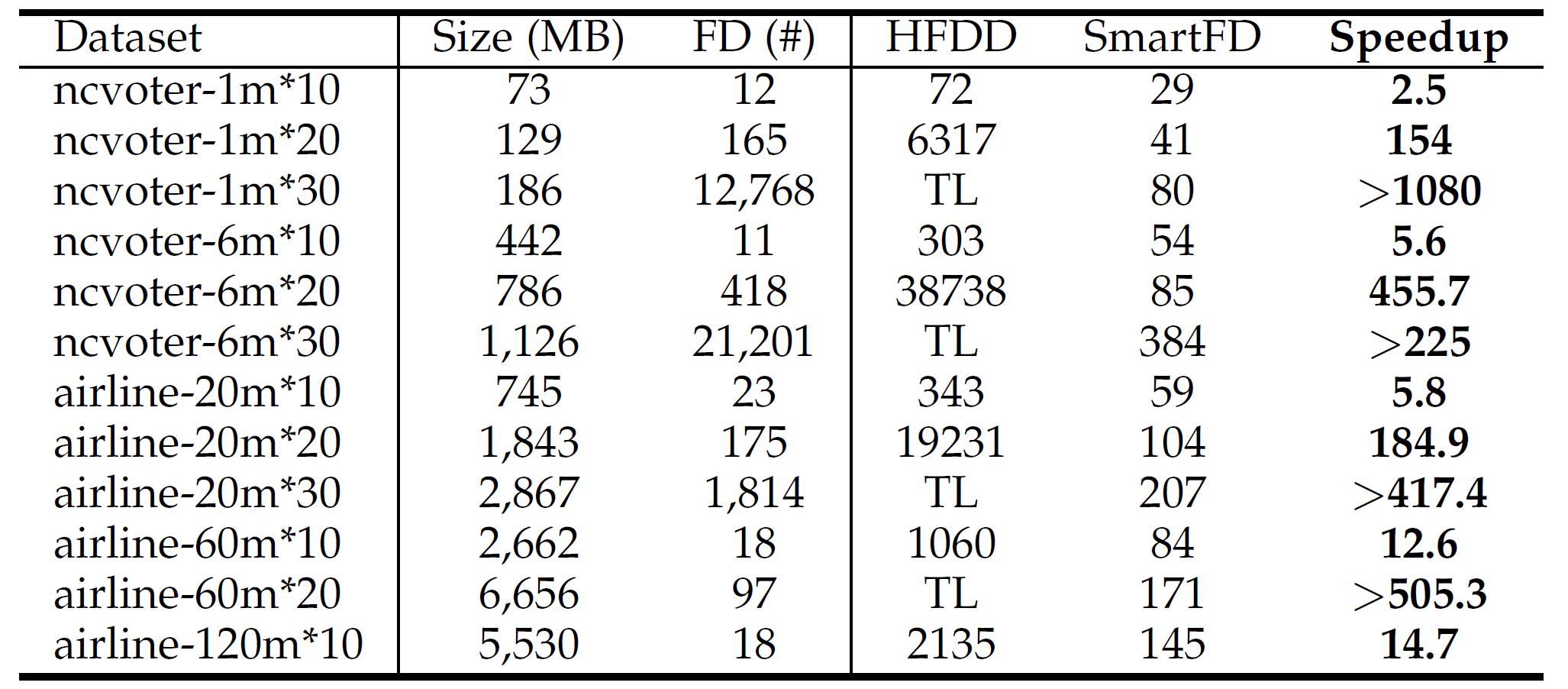
HFDD是目前已有的分布式FD发现算法[3]。表2显示了SmartFD与HFDD的性能对比结果。从表2我们可以看出,HFDD在所有包含30列的数据集上均运行超时,列扩展性较差。相比之下,SmartFD具有良好的列可扩展性。而且,在小于30列的数据集上,SmartFD能够实现2.5到455.7倍的加速比。
4.3 节点可扩展性评估
我们也分析了SmartFD算法的节点可扩展性。图7显示了SmartFD运行时间随着计算节点数的变化情况。随着计算节点数量的增加,SmartFD运行时间呈现出近线性下降的趋势,表明SmartFD具有较高的节点可扩展性。
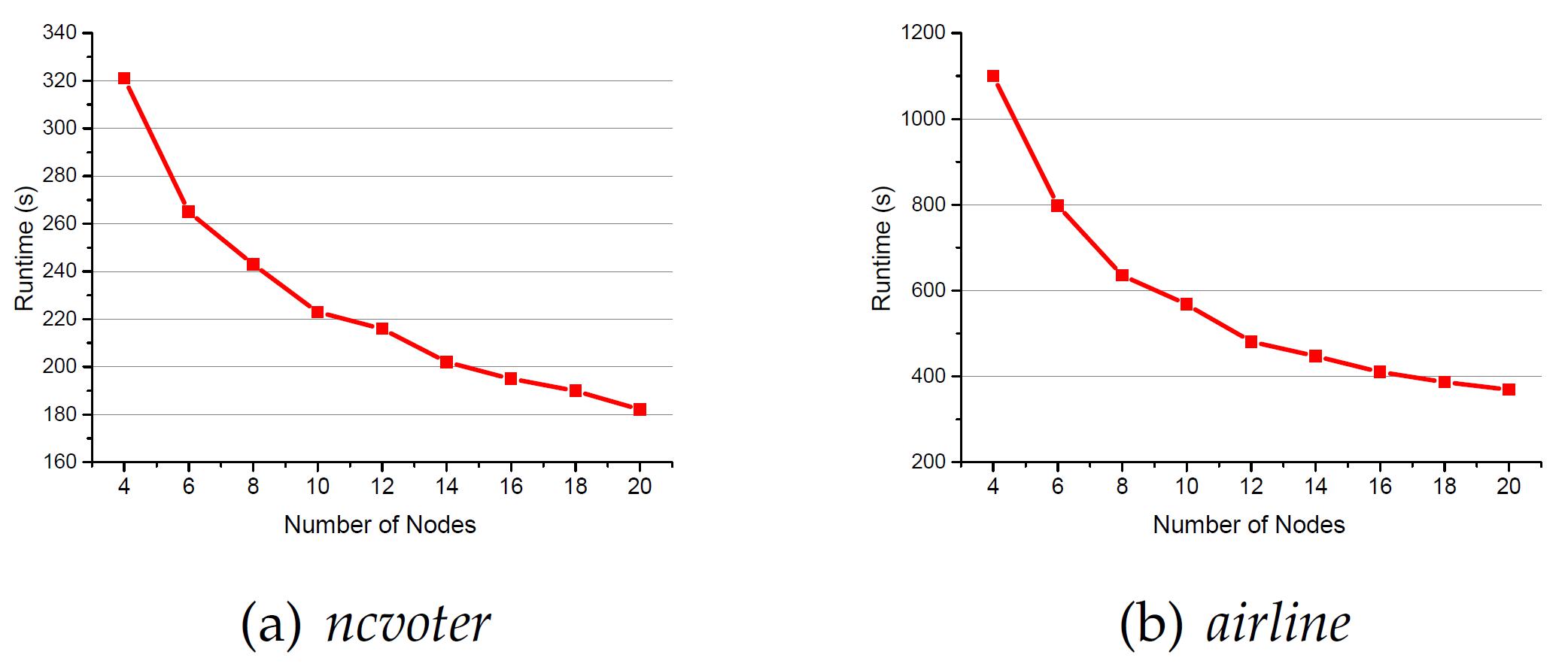
图7 节点可扩展性评估
5、总结与展望
函数依赖是关系数据库中一种最为常见的约束条件,应用场景广泛。但是目前已有的函数依赖发现算法均不能高效地处理大规模数据集,存在时间开销和内存开销巨大的问题。为此,本文研究提出了一种高效可扩展的大规模分布式函数依赖发现算法SmartFD。SmartFD在基于属性排序的算法框架下,通过高效的分布式采样、分布式验证以及自适应的采样-验证切换策略,能够以较少的运行时间开销和内存开销处理大规模数据集。与已有的函数依赖发现算法相比,SmartFD能够实现1-2个数量级的性能提升。而且,SmartFD具有良好的数据可扩展性以及近线性的节点可扩展性。
未来,我们准备将SmartFD应用在更多的大规模数据管理任务中,例如数据治理、数据库查询优化等。同时,我们也将进一步研究大规模分布式条件函数依赖以及近似函数依赖等算法。
参考文献
[1] J. Liu, J. Li, C. Liu, and Y. Chen, “Discover dependencies from data-a review,” IEEE Transactions on Knowledge and Data Engineering (TKDE), vol. 24, no. 2, pp. 251–264, 2011.
[2] T. Papenbrock and F. Naumann, “A hybrid approach to functional dependency discovery,” in Proceedings of the ACM International Conference on Management of Data (SIGMOD), 2016, pp. 821–833.
[3] S. Tu and M. Huang, “Scalable functional dependencies discovery from big data,” in Proceedings of the IEEE International Conference on Multimedia Big Data, 2016, pp. 426–431.



