

2019-07-26
分享到作者:顾荣、周余发
本篇将分享南京大学PASA大数据实验室与江苏鸿程大数据研究院大数据系统组在大规模数据回放方向的研究工作。
该工作的论文发表在分布式并行计算领域顶级期刊IEEE Transactions on Parallel and Distributed Systems (TPDS, SCI期刊)上,论文题目为: Efficient Query-based Framework for Replaying Large Scale Historical Data. 可以从IEEE论文数据库中获取。
近年来,随着信息技术的不断发展和普及应用,各行各业都积累了大规模数据资源。为了能够有效地分析处理这些数据,涌现了各种大数据计算模式和处理平台,包括批处理、查询分析、机器学习、图计算以及流计算等计算模式与系统。
然而,在线系统性能测试、历史证券数据分析回测平台以及推荐系统等应用中有一种较为特殊、不同于上述处理模式的历史数据回放应用服务需求,而现有的大数据技术与系统都难以直接支撑这种大规模数据回放应用服务需求。
数据回放服务是指对静态历史数据按照用户给定的条件进行查询,并以流数据方式传输到上层应用系统进行回放的一种数据服务。图1展示了一个数据回放服务系统的基本处理流程和系统构架。其中,最底层为静态历史源数据,中间层为回放系统(类似于一个数据库系统DBMS),而最上层为构建于回放系统之上的具体回放应用服务(类似于一个数据库应用系统)。用户可以根据具体的数据回放服务需要,通过中间层的回放系统对底层历史数据进行查询,得到一系列中间结果,这些中间结果再由用户指定的逻辑操作进行特定的处理,最后将结果转化为动态的回放数据流,并推送到上层的回放应用服务程序中向用户进行回放。
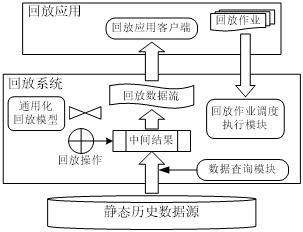
图1:回放服务系统处理流程与系统框架
在数据回放服务应用场景下,底层的大规模历史数据可由用户根据需要进行一定条件的查询,然后按照特定的回放顺序(例如,回放记录中的时间戳的顺序)进行回放处理。例如,一个离线股票量化分析平台可以回放某些股票在过去一年的交易记录,并对这些历史交易数据进行分析,从而发现一定的规律。由于数据回放服务中涉及的回放数据量可能十分巨大,上层回放应用不能简单地从数据库中查询存储结果数据,然后再对存储结果进行回放。这是因为回放数据量巨大,上层应用在开始回放之前需要等待大量的时间。代之以这种简单低效的处理方式,对于大规模数据集回放服务需求,需要构建并提供一种高效的查询和流式回放处理能力。
在上述场景下,无论是现有的流计算系统,还是数据库系统,都无法以高效且易用的方式支持大规模数据回放服务。一方面,流计算系统虽然提供了流处理的能力,能够以流数据服务方式加载和处理数据,但它们无法满足数据回放服务的一些基本需求。另一方面,数据库系统主要用于在静态数据集上执行特定的查询,并且以批处理的方式而非流处理的方式将查询结果返回给用户,它们本质上缺乏流处理的能力。此外,当数据量很大时,传统数据库很难保证数据回放服务的性能。
针对上述问题和技术难点,我们将流处理的特性与复杂查询处理的特性相结合,研究提出了一种通用化的数据回放模型,并据此设计实现了一个大规模数据回放系统Penguin,以支持大规模历史数据回放服务和应用。我们主要研究工作和贡献点如下:
(1)研究构建了一种通用化数据回放模型和框架,并针对该模型和框架,构建了一系列内置的标准回放操作符,用于表达回放模型中的各种处理逻辑与回放语义。
(2)基于上述统一数据回放模型和框架,研究并设计实现一个高效的分布式数据回放系统Penguin。该系统支持回放应用开发者开发具备高吞吐量的回放应用程序,从而对来自多个底层数据源的大规模历史数据进行查询和回放处理,同时该回放系统还提供了回放速率调节功能,并保证了回放速率的QoS。
(3)为了进一步提升该回放系统的回放性能,研究实现两个底层优化技术,包括源数据缓存优化技术以及单数据流并行化生成技术。
(4)性能测试实验结果表明,与Apache Phoenix和Apache Hive相比,在数据准备阶段,本文系统Penguin可分别达到2.5倍和47倍的加速比;在回放阶段,Penguin可分别达到8倍和7倍的加速比。
(5)作为实际落地应用案例,本文实现的回放系统已部署在国内某大型券商的生产线中,为其提供金融证券数据高速回放服务。
一个数据回放服务应用中的回放作业,由底层数据源以及若干回放操作符连接构成的有向无循环图(Directed Acyclic Graph,DAG)所定义。其中,底层数据源存储的静态历史数据作为回放作业的输入,回放操作符连接构成的DAG定义了需要对数据进行的一系列回放处理逻辑操作。回放作业启动后,底层的源数据先被加载到回放系统中,接着经过回放操作符DAG所定义的回放处理逻辑进行的查询和处理后,得到查询结果,最终以动态回放数据流的形式推送给上层的回放应用,并在应用客户端向用户回放。
本文回放系统可对来自底层多个异构的数据源中的静态历史数据进行回放,对回放应用客户端而言,这些源数据是只读的,不能够通过回放系统对底层数据源中的数据进行任何更新操作。回放系统可提供对多种主流数据源的支持(例如分布式文件系统、传统SQL数据库、NoSQL数据库),此外,用户也可按照本系统定义的统一数据抽象接口实现对新的数据源的支持,并无缝对接到现有系统中。
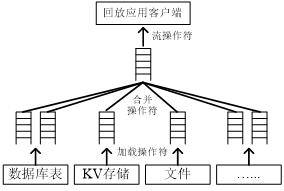
图2:回放作业数据流模型
回放作业的数据流模型如图2所示。回放作业的数据流一共要经过三个阶段,即数据加载阶段、合并阶段、流处理阶段。这三个阶段分别由加载操作符、合并操作符、流操作符完成。
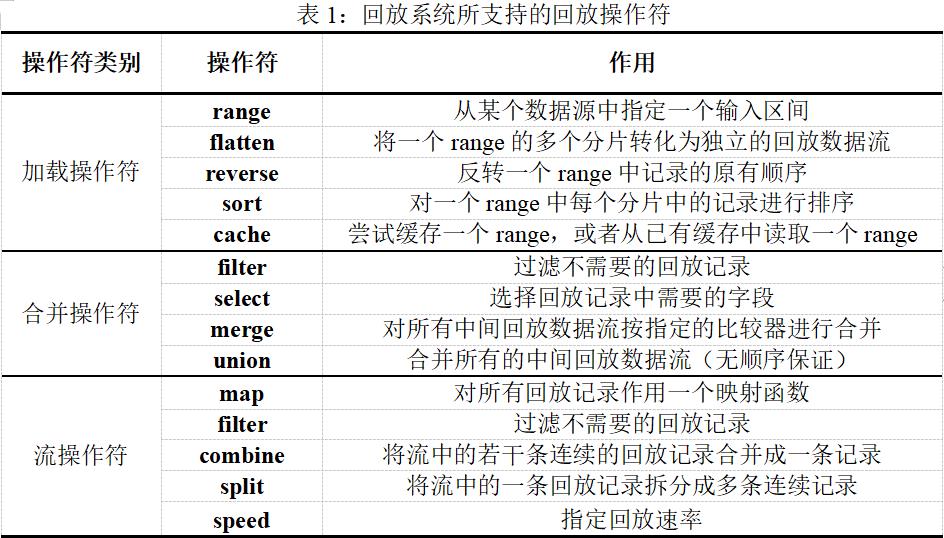
本文研究实现的回放系统所支持的回放操作符分为3类:加载操作符、合并操作符、流操作符。其中,加载操作符用于将底层异构数据源中的静态数据加载成回放系统中的中间回放数据流,合并操作符用于将多个中间回放数据流合并成单个回放数据流,流操作符用于对合并后的单个回放数据流进行相关的流处理。本文回放系统构建了见表1所示的回放操作符。
本节介绍回放系统为回放应用开发者提供的编程模型与示例。其中编程模型需要使用前文所述的回放模型中的各种回放操作符构成一个回放作业DAG,从而定义一个回放作业。回放系统向用户提供了一个简单易用的Java编程接口,从而允许回放应用开发者快速使用这些接口编写具有复杂业务处理逻辑的回放应用。
在开发一个回放作业时,其核心在于定义好该回放作业模型,即使用前文所述的3种回放操作符组成一个DAG,如图3所示。图中,除了range操作符必须指定外,其他操作符都是可选的。另外,这3种回放操作符在DAG中是有顺序要求的,加载操作符必须在最底层,中间为合并操作符,最上层为流操作符,不同种类的操作符在该DAG中不能交叉放置。
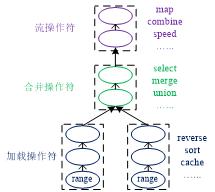
图3:回放作业模型DAG
下面,我们举一个基于上述数据回放编程模型开发的具体日志应用示例,该示例为对大量LOG日志文件中的WARN和ERROR信息进行回放。目前,几乎所有主流的分布式系统都会在每个节点上产生一些日志文件,以便于对系统进行监控和错误定位。由于这些日志信息分散在众多日志文件中,当需要对某些警告信息或者错误信息进行定位时,普遍的做法是人工去查看每个日志文件。然而,当日志文件数量过大时,这种方法十分低效。另外,如果系统的某个错误导致了多个不同节点先后产生了一系列的错误事件,那么需要在多个不同日志文件中不停切换定位相关错误日志信息,这在更大程度上加重了调试人员的负担。
事实上,考虑到每个日志文件内部的日志信息都是按照时间戳升序的,假如能够将所有日志文件中的日志信息汇总起来,并通过过滤操作符只保留其中的WARN和ERROR信息,按照其时间戳进行升序组织,最后以单个日志流的形式返回给调试人员,那么将极大地提高调试效率。
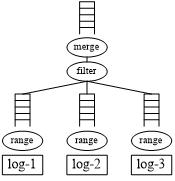

(a) 日志文件回放作业数据流 (b) 日志文件回放作业代码
图4:日志文件回放作业示例
图4是上述日志文件WARN和ERROR日志信息的回放作业示例。图4(a)为该回放作业的作业模型,其中,对于每个日志文件,都使用一个range操作符进行加载,接着使用一个filter操作符过滤出其中的WARN和ERROR日志,最后使用一个merge操作符将来自多个日志文件中的日志信息按照其时间戳进行比较合并。由于每个日志文件中的所有日志信息已经按照时间戳升序组织了,因此经过merge操作符后,所有的日志信息都将按照时间戳进行升序组织,最后得到的结果即为按时间戳升序的单个日志信息数据流。
图4(b)为该日志文件回放作业的实现代码。在该代码实现中,首先创建了一个ReplayStream对象以代表图2-6(a)中的DAG图,接着为每个日志文件都添加了一个TextRange对象,然后添加了filter和merge操作符对日志消息进行过滤和排序,最终进行日志消息的回放。其中,LogFilter类即用户自定义的filter操作符,用于筛选出WARN和ERROR日志消息;LogMerger类即用户自定义的merge操作符,用于按照时间戳对日志消息进行比较合并。
本文回放系统Penguin的整体系统架构如图5所示,图中的进程可分为两组,即后台进程和会话进程。后台进程包括一个Master和多个在不同节点上的Worker;会话进程包括Server和Executor,以及回放作业Client,在同一个回放作业会话中,有且只有一个Server进程,但Executor进程可以有多个。由于后台进程是常驻的,在同一个节点上,只会有一个Worker进程用于管理该节点的资源,但由于回放作业会话可能有多个,因此同一个节点上可能会有多个Server或者Executor进程。
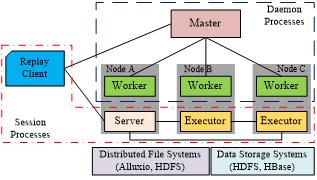
图5:分布式回放系统Penguin系统架构
回放作业的执行流程如图6所示。图中,整个执行流程分为以下9个步骤:
(1)Client向Server端发起回放作业请求;
(2)Executor向Server端请求加载任务;
(3)Executor加载源数据;
(4)Executor生成中间临时文件;
(5)Server为Executor分配合并任务;
(6)Executor合并回放数据流;
(7)Server合并最终单一数据流;
(8)Server执行流操作处理;
(9)Server向Client推送回放数据流。
注意,在上文中已提到,回放作业是以流水线的方式而非批处理的方式进行的,这是因为这里的9个步骤除了步骤1仅在开始执行了一次,其他8个步骤都是以流水线的方式执行,从而使得整个回放作业能够以流水线的方式进行。
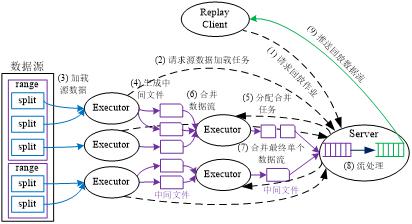
图6:回放作业执行流程图
对于设定了speed操作符的回放作业,系统需要按照其指定的回放速率(符合范围的)进行回放,从而保证回放作业过程的稳定性。如果是常规的批处理作业,则完全可以先准备好所有的回放数据,再按指定的速率进行回放,且因为数据已经完全准备好,其回放速率理论上可以十分稳定。然而,由于整个回放过程是以流水线方式执行的,在回放执行的过程中,可能会有一部分数据还未处理,因而无法采用该方法。本文采用“准备测速-回放”两阶段的回放机制来保证回放速率的稳定,即先准备一部分数据而不开始回放,在准备过程中同时测量该作业能够支持的最大回放速率,接着按不超过该最大支持速率的回放速率进行稳定回放。
一个回放作业的执行过程中包括两个阶段:即准备阶段以及回放阶段。在准备阶段中,数据加载任务、合并任务以及流处理任务以流水线的方式并行执行,且Server将生成的回放数据流添加到发送缓存队列中,在该过程中Server会测量回放记录的生成速度,从而得到一个针对该回放作业支持的最大回放速率。当发送缓存队列中的记录数达到配置阈值时,准备阶段结束,进入回放阶段,Server将测量出的最大支持回放速率返回给回放作业Client,从而Client只能够设置该最大速率以下的回放速率进行回放。
当回放作业进入回放阶段后,上文所述的分布式级联合并中的各个分布式文件队列都已经缓存了一些已生成且未消耗的中间数据文件,且Server中的发送缓存队列也缓存了一部分回放记录,由于回放速率不会超过准备阶段所测量的最大回放速率,因此,只要整个回放系统保持相对稳定,这些缓存的中间数据文件以及回放记录便可以保证整个回放阶段中回放速率的稳定性,从而保证回放服务的QoS。
我们在拥有1个主节点和7个计算节点的集群中对本文设计实现的Penguin系统进行了性能评估,本节摘录部分实验结果。Penguin系统基于HBase和Alluxio实现,我们对比了Hive和Apache Phoenix系统。
图7展示了Penguin与Apache Phoenix和Apache Hive在不同回放作业场景下针对不同的数据量进行查询的性能对比结果。对于本文回放系统Penguin,对不带源数据缓存(uncached)和带100%源数据缓存(cached)两种情况都进行了查询性能测试。对于单表按主键排序查询作业,其性能测试结果如图7所示。由于Penguin自身的流处理特性,其回放速率(不包括准备时间部分)最高可达到Phoenix的8倍,Hive的7倍。对于单表按非主键排序查询作业、多表按主键排序查询作业、多表按非主键排序查询作业,Penguin随着数据规模增大运行的稳定性比Phoenix强,且运行总体性能比Hive高。

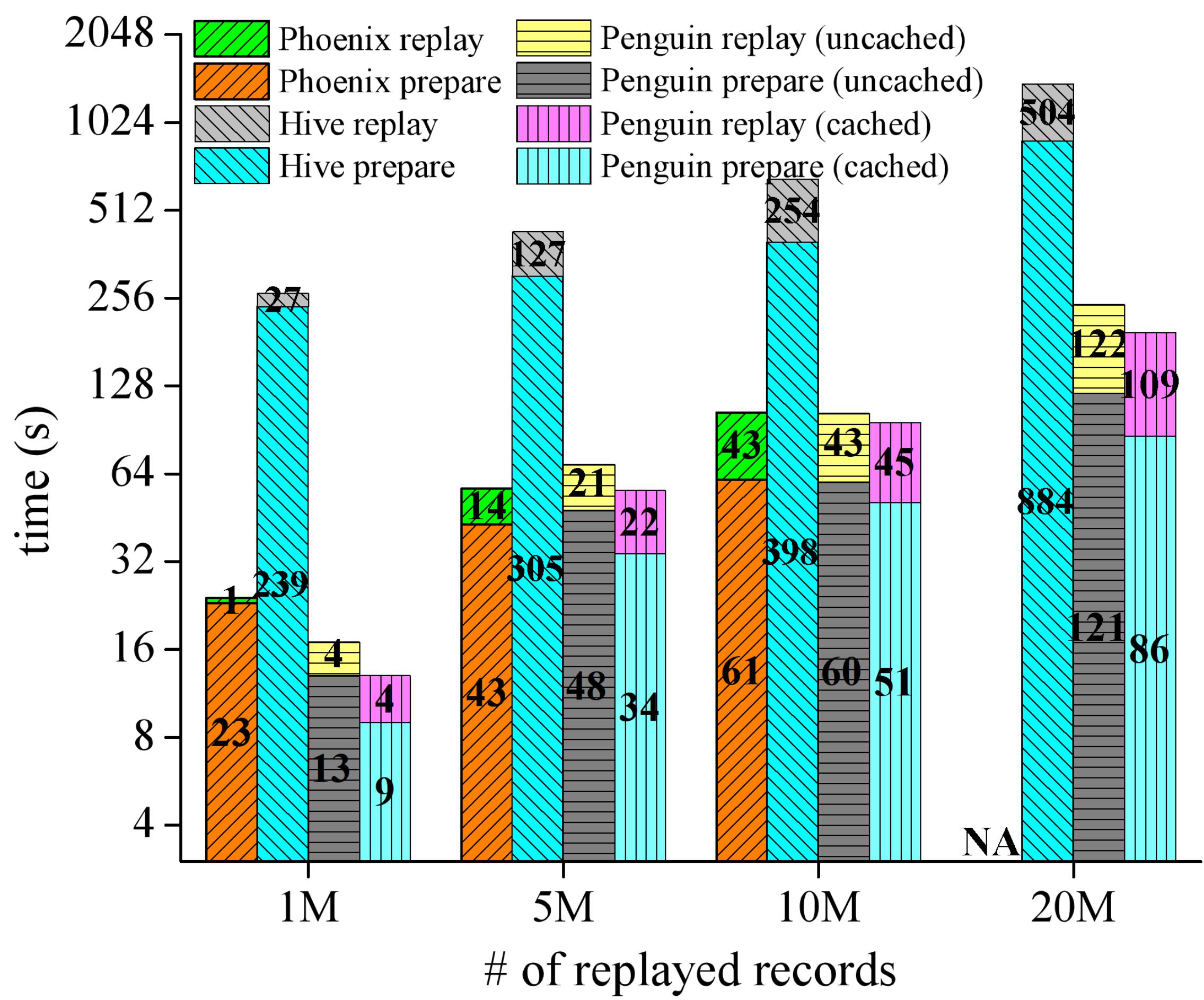
(a) 单表按主键排序查询 (b) 单表按非主键排序查询

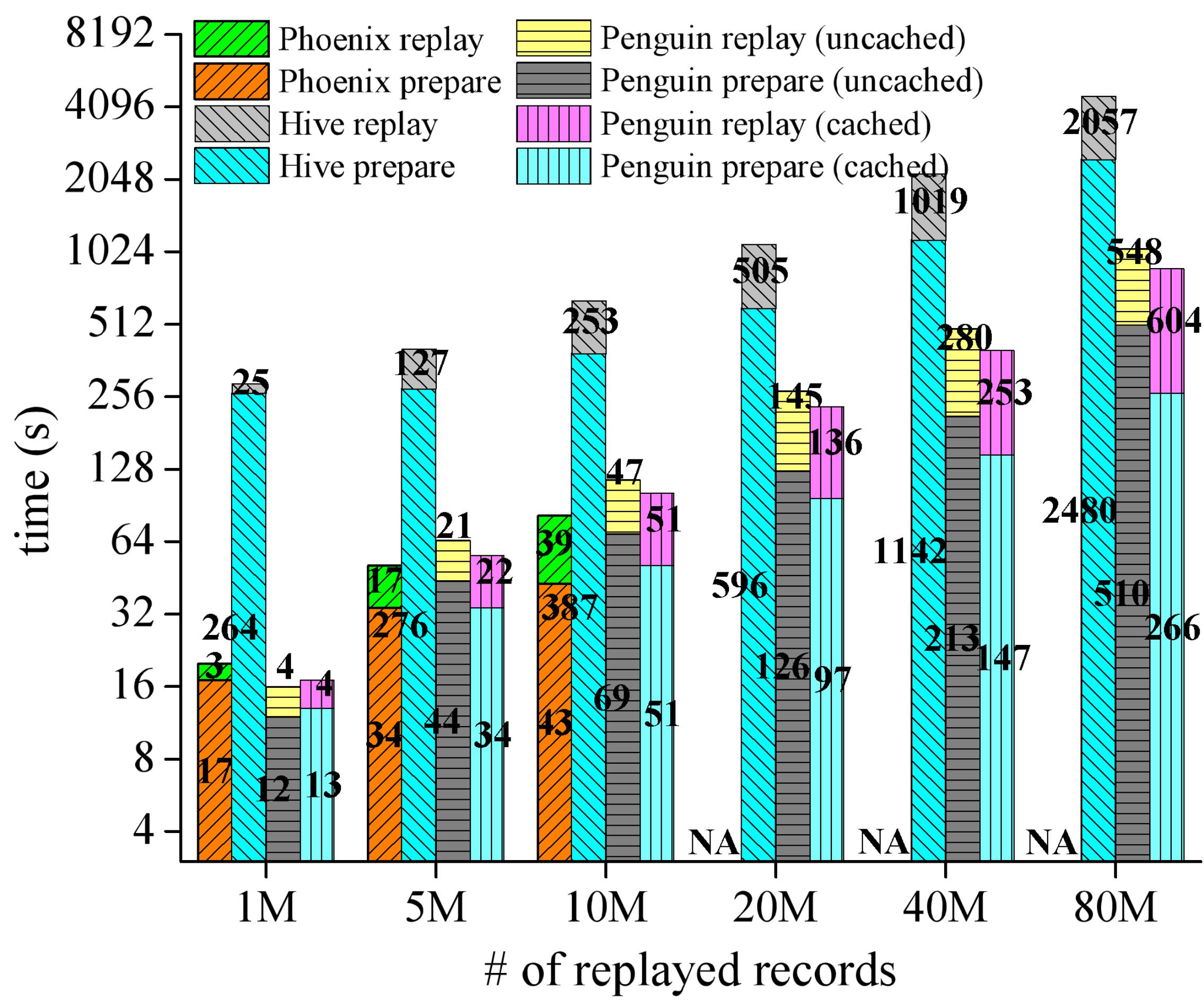
(c)多表按主键排序查询 (d) 多表按非主键排序查询
图7:Penguin与Apache Phoenix、Apache Hive查询性能对比
图8展示了本文回放系统Penguin的可扩展性,包括数据可扩展性和节点可扩展性。图8(a)为回放时间随着回放数据量增大的变化曲线,该测试实验对4个表格数据按照主键字段进行排序并回放。从图中可以看出,回放时间随着数据量的增加而线性增加,即回放速率保持恒定。图8(b)为不同的Executor数量对回放性能的影响,该测试实验对的单个表格数据按照非主键字段进行排序并回放。从图中可以看出,随着Executor数量的增加,准备时间和回放时间都显著下降,当Executor数量增加到7时,相比于1个Executor的情况,准备时间和回放时间分别下降了44%和37%。本节实验说明Penguin具有良好的数据可扩展性和节点可扩展性。
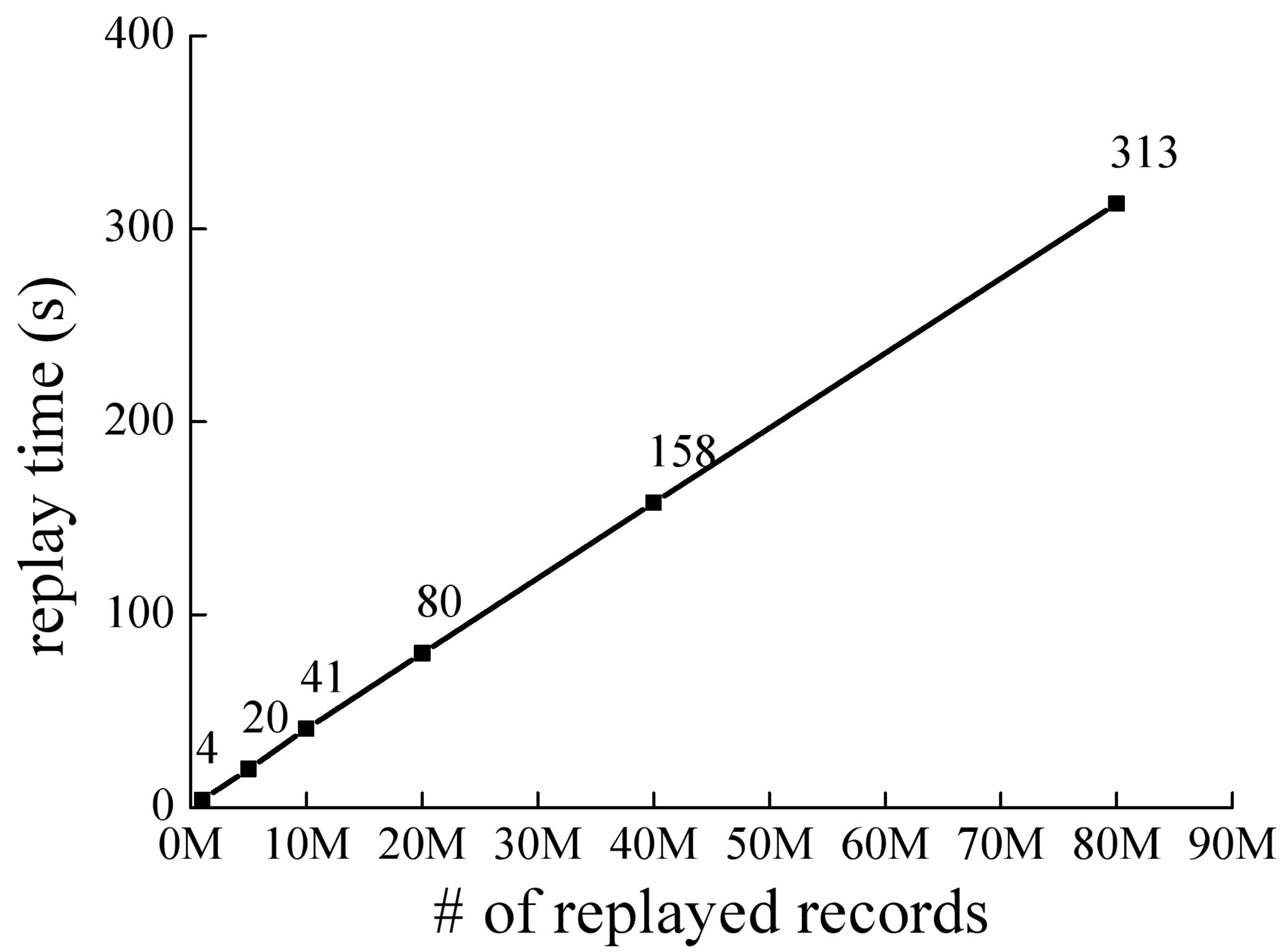
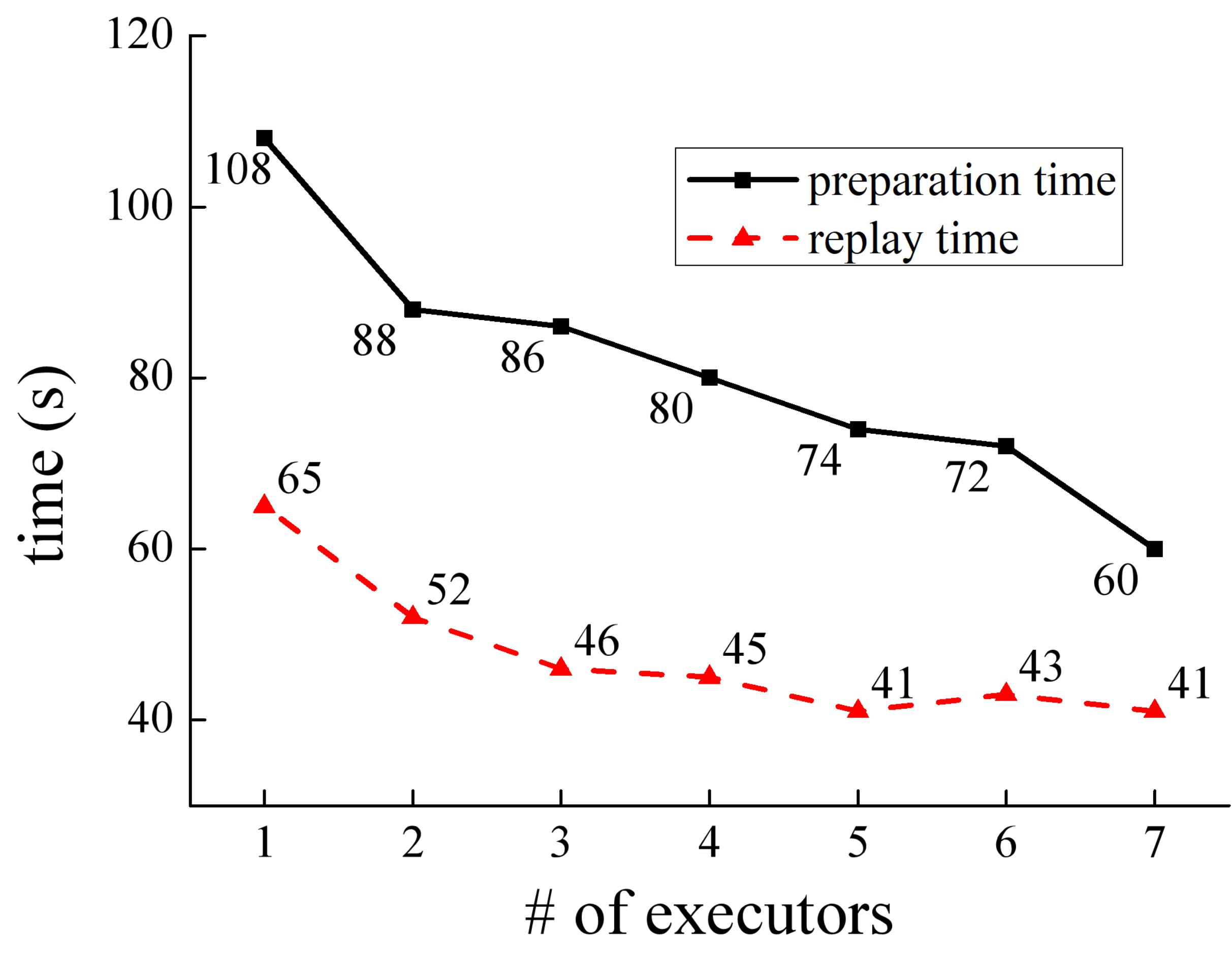
(a)数据可扩展性实验 (b) 节点可扩展性实验
图8:Penguin系统的数据可扩展性及节点可扩展性实验
本文针对大规模数据回放服务这类迫切的应用需求,为上层回放应用提供了一个通用化数据回放模型与框架。在编程易用性方面,本系统提供了简单灵活的回放操作符,支持用户针对具体业务自定义复杂的回放逻辑,在具体编程实现中,使用主流的Java编程语言向用户提供了简单易用的回放API,允许用户编写少量代码即可完成数据回放应用程序的编写;在多数据源支持方面,本系统目前已支持主流的文件系统、SQL数据库及NoSQL数据库,并且允许用户无缝接入新的数据源;在回放服务质量方面,本系统提供了回放速率调节功能,且系统内部会保证回放速率的QoS。
在未来,进一步工作主要包括两方面。一是提供对更多底层数据存储系统的支持,从而允许回放应用对更多静态历史数据进行回放处理;二是支持提供更多的回放操作符,例如join和window aggregation等,从而支持更加复杂的回放逻辑。

