

2020-09-04
分享到需求背景与产品简介
大数据和人工智能已经成为国家重要战略,数据更是成为与传统生产要素同等重要的生产要素。为了有效完成大数据处理与智能化分析应用,过去10多年来,大数据编程计算技术得到快速发展,国内外出现了众多大数据系统平台,为行业大数据分析应用提供了多样化的选择。
但与此同时,众多系统平台相互不统一,缺少互操作性,编程方法与编程语言环境不同,并且编程技术门槛高,难以为普通行业大数据分析人员学习和使用。同时,行业大数据综合分析应用,往往不是单一的分析处理,而是会涉及到多种不同的数据模型和计算模式,例如,数据库查询分析、机器学习、深度学习、图计算、以及流式计算。为此,需要提供一种易于学习和操作使用、跨平台统一化的大数据分析处理与编程开发平台。
为此,江苏鸿程大数据研究院推出了跨平台统一大数据分析处理与可视化编程平台。本平台可提供丰富的数据存储管理与数据处理能力,提供数据库查询分析、机器学习、图计算、流式计算等多种大数据计算模式与建模分析功能,这些功能以图标化算子形式内置在系统中,用户能通过拖拽方式,在无需代码编程的情况下,方便快捷地开发数据分析处理程序和算法模型。平台底层可根据需要集成使用各种主流大数据存储与计算系统,实现跨平台统一大数据处理与智能分析编程与应用开发。平台可广泛应用于各类行业和企业的大数据处理与智能化分析应用开发,从而大大降低大数据分析处理与建模门槛,提升大数据智能化应用开发效率。
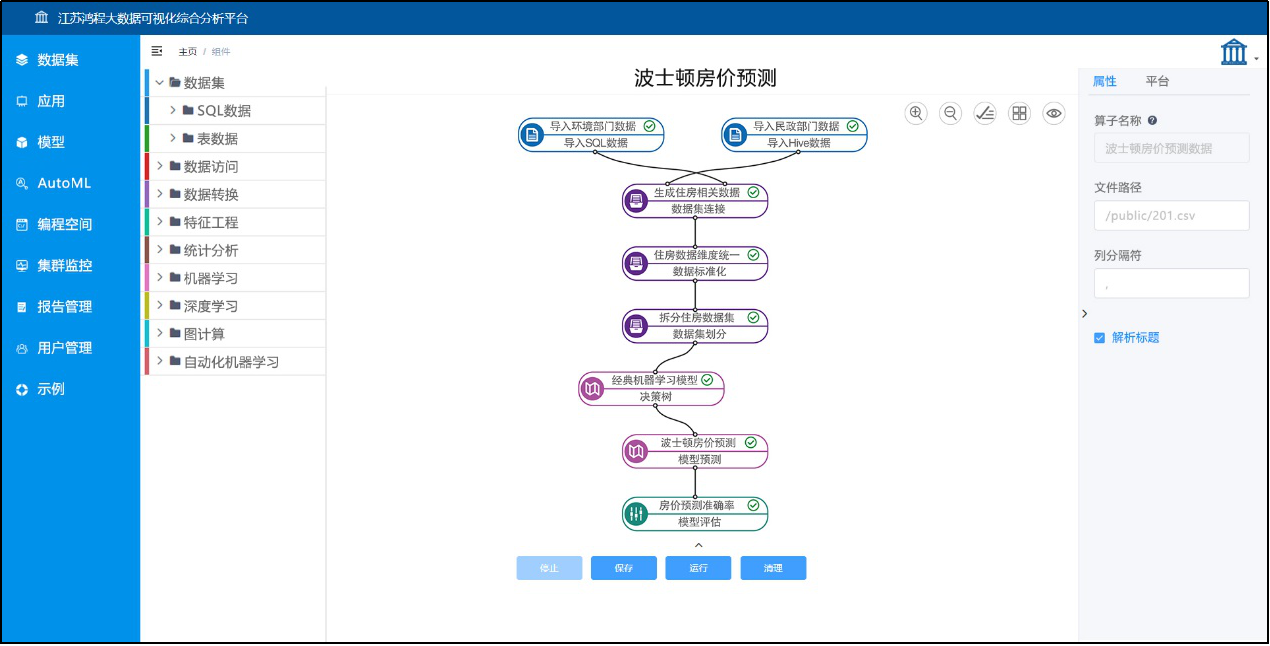
图1:可视化拖拽式建模分析界面
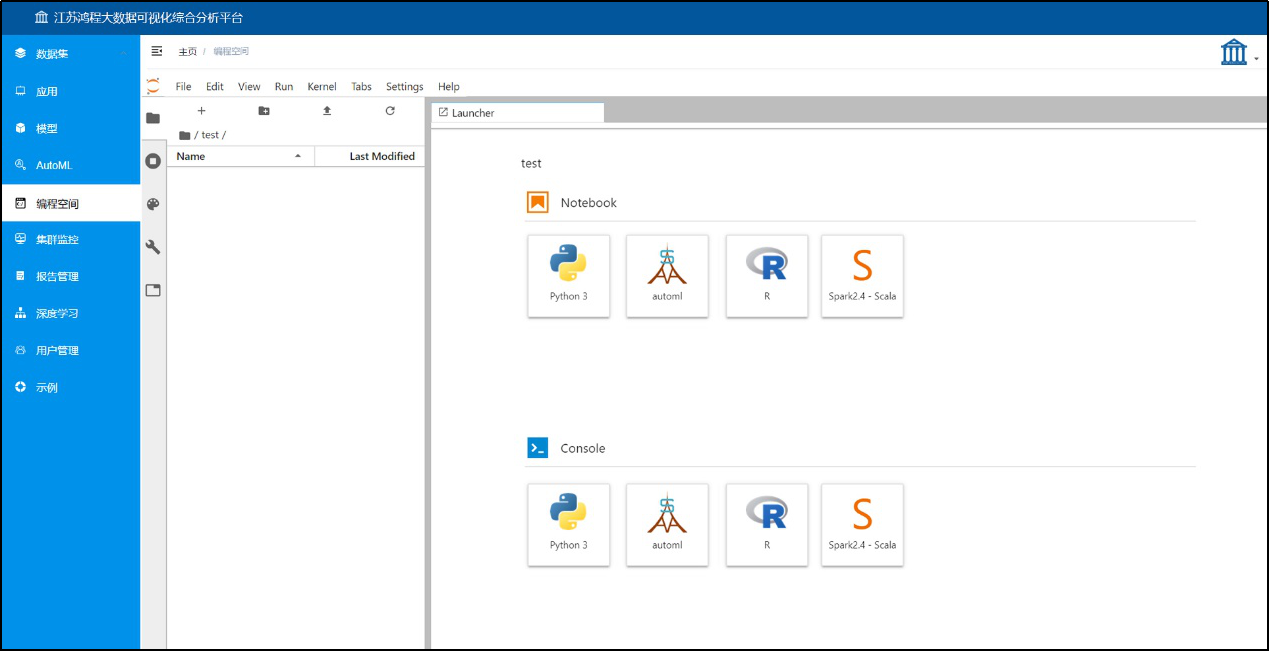
图2:编程工作空间界面
产品主要功能
■ 可视化拖拽式与程序代码双编程模式:面向普通数据分析人员,支持基于可视化计算流图和算子免代码拖拽式编程,可视化流程图和算子可提供算法名称和业务名称双模式显示。同时也支持Python、R、Scala程序设计语言代码编程开发模式。
■ 多模式跨平台统一大数据分析处理:跨平台统一的大数据编程计算环境,支持数据查询、图计算、机器学习、深度学习、流式计算等多种计算模式,底层可集成使用Hadoop、Spark、Tensorflow、Scikit-learn、Flink等各种主流大数据系统,支持平台选择和混合调度。
■ 多数据存储管理系统支持:支持HDFS/Alluxio等分布式文件系统、HBase/Hive分布式数据库、MySQL及Oracle等关系数据库、以及Neo4j等图数据库,并可根据需要集成各种主流分布式数据库,实现企业多数据源的无缝集成和使用。
■ 丰富的数据分析处理算法:以算子形式提供近80个性能优异的数据分析处理算法,包括常用数据处理、数据查询、统计分析、机器学习、深度学习、图计算、文本分析算子,满足用户多样化数据分析需求。支持用户自定义复合算子,提供行业复杂业务算子构建能力。
■ 集成自动化AI建模技术:内置国际先进水平的AutoML自动化建模工具,支持传统机器学习和深度学习自动化建模,可自动化完成包含数据与处理、特征工程、模型选择、超参数优化在内的AI建模,大幅降低AI建模门槛,提升建模效率,减少人力成本。
■ 丰富的可视化数据分析与展现:集成Echarts报表可视化插件包,支持柱状图、散点图、饼图、热力图以及网络关系图等丰富多样的数据可视化展现方式,同时也支持常用算法模型的可视化,可帮助用户从多个维度了解建模流程中的数据变化情况。
■ 文本图像标签管理:内置标签管理,支持图片数据、文本数据的多分类、多标签、目标检测、词性标注等任务在线打标,从而实现依托于平台的全流程文本图像任务训练。
■ 高效的模型管理与共享使用能力:支持用户开发共享复杂业务模型,对计算流图中的分析模型可进行一键保存,将训练好的模型加入模型库,保存后的模型可提供方便的共享复用,并支持快速部署上线服务,并能以RESTful API接口对外提供模型预测服务。
■ 用户管理与多租户资源共享:平台支持管理员、租户管理员和普通租户等多种用户的操作使用权限管理,并支持多租户资源共享调度和隔离,在提升资源共享使用效率的同时,提供资源安全隔离保护能力,保证用户计算资源的安全使用和应用系统的稳定运行。
■ 系统监测与运维功能:平台底层基于开源可靠的企业级前后端框架,利用Docker容器化一站式快速部署,内置Netdata资源监控面板,提供整个系统及平台后端应用运行状态的监测能力,提供高效的系统运维管理能力。

图3:可视化数据分析界面
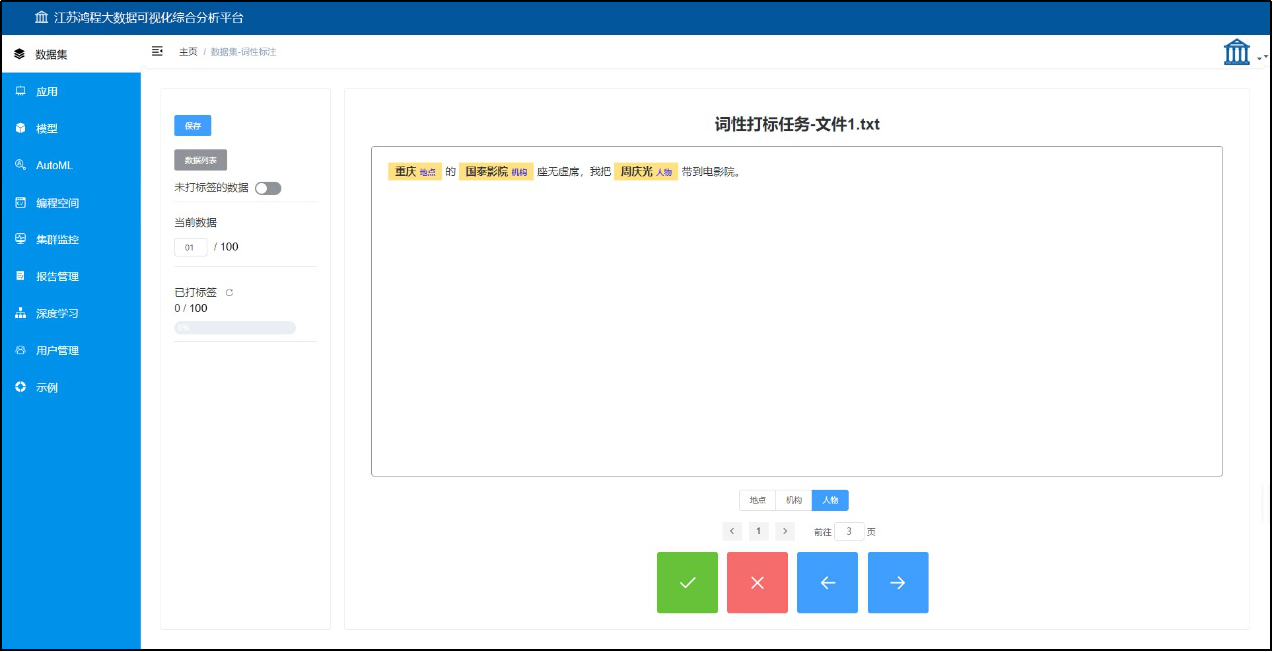
图4:文本数据打标签界面
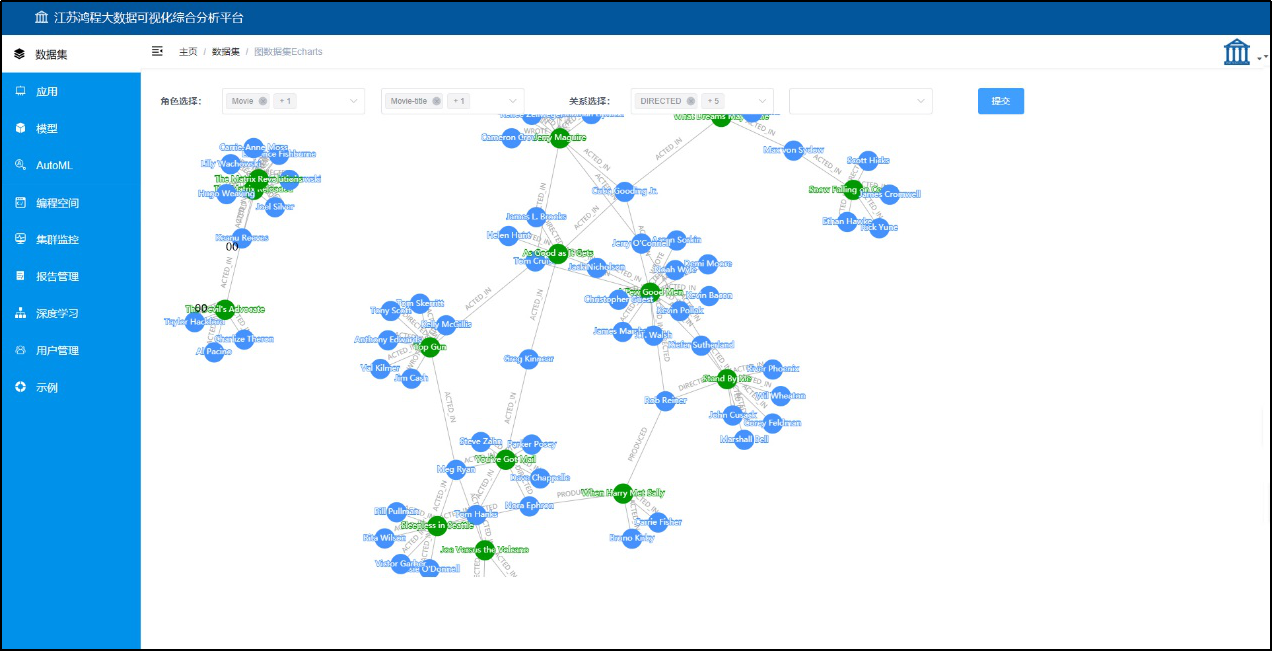
图5:图数据库可视化
AutoML自动化AI建模
本平台内置了南京大学PASA大数据实验室与江苏鸿程大数据研究院共同自主原创、国际先进的AutoML技术。用户仅需给定数据和预算时间,无需人工干预,平台即可自动化实现机器学习流水线的自动化设计,将数据预处理、特征工程、模型选择以及超参数调优等步骤交由平台自动完成,从而实现AI模型的自动化构建。平台支持传统机器学习和深度学习的自动化建模,并可面向宽表、多表、图像、语音、文本、时序数据等不同数据类型完成自动化建模。在模型性能不低于人工专家的前提下,能够大幅提高AI建模效率,从而降低AI使用门槛,让AI为人人所用。

图6:AutoML建模和人工专家建模对比
PASA-AutoML连续多次在国际著名的AutoML大赛中以优异成绩获奖(PAKDD 2018 AutoML、NeurIPS 2018 AutoML、 KDD Cup 2019 AutoML、NeurIPS 2018 AutoDL等),其中NeurIPS、KDD、PAKDD均为人工智能/数据挖掘领域的国际顶级会议。因此,PASA-AutoML总体处于国际先进水平。另外,该技术已在华为、奇虎360等IT企业和其他行业中落地应用,并于2019年10月在第五届中国“互联网+”大学生创新创业大赛中荣获全国金奖。

图7:PASA-AutoML所获奖项
平台产品架构
平台底层支持Alluxio、HDFS、HBase、Hive、关系型数据库、分布式数据库、图数据库等存储系统,上层通过跨平台统一计算任务调度实现了单机Scikit-learn、Spark、Flink、Tensorflow、Pytorch等主流计算平台的混合调度,从而支持数据查询分析、机器学习、图计算、深度学习等数据分析任务以及AutoML自动化AI建模和调优。基于计算流图的可视化拖拽式编程,可以快速构建业务模型并上线部署,从而服务于各行业的大数据分析和应用,为大数据分析建模降本提效,加速产业数字化应用落地。

图8:平台总体架构
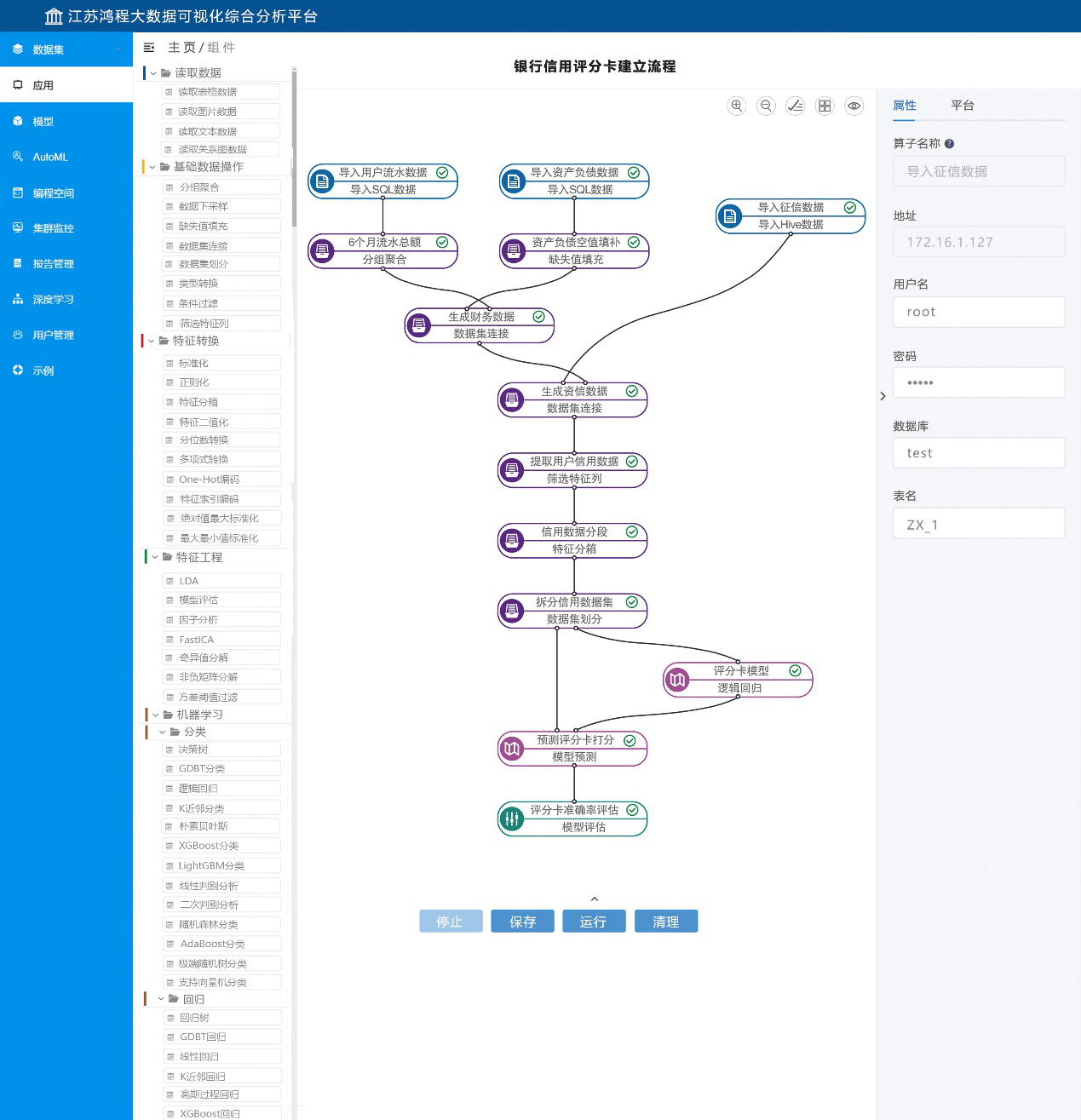
图9:银行评分卡案例程序流程


