前言
大数据时代,数据如同空气在我们的生活中无处不在,随着国家大力推行数字经济、数字化转型,越来越多的人和组织机构认识到了数据的重要性。但是数据犹如一把双刃剑,它能给业务带来巨大便利和价值的同时,也会带来极大的风险。数据的质量问题就是风险所在。一方面,低效错误的数据常常带来的是错误的认知,错误的认知将会直接导致高层领导的决策失误,对业务产生不可计量的后果。另一方面,想要数据发挥其内在价值,数据的质量一定要高。高质量的数据是一切数据应用的基石。如何在数据中台构建完备的数据质量检测流程,成为数据中台不可缺少的功能之一。
什么是数据质量
数据质量是指数据在业务场景中能够满足业务场景的需求,能够符合数据消费者的使用目的。数据质量包含两个方面,一是数据本身的质量,二是数据的过程质量。数据本身质量是指数据在业务场景中能够真实记录实际发生的业务,任何的业务数据都没有被遗漏,并且数据自身的约束条件都没有任何的冲突。例如:业务部门在数据录入过程中不小心输入了错误的数据或是漏输了部分数据等。
数据的过程质量是指数据在使用过程中,能被正确的使用、存储、传输等。如:数据在存储时是否因为存储介质不合适,导致数据丢失或者无法读取等。
数据质量问题产生原因
数据充斥在我们生活的方方面面,我们或多或少都会遇到以下类似的数据质量问题,例如:某日数据增量异常,日增1000万变成日增3000万甚至更多。某类数据缺少某些维度信息,无法对该数据做进一步的数据分析。数据质量问题产生的原因有很多,并且通常是多个因素共同导致的。比如一个政府单位,其下辖单位各自建有符合各自标准的信息系统,自己产生数据的同时,还接受下级单位的数据,这样就导致该政府汇聚了大量不同标准的数据、重复的数据。这些问题从本质上来看,还是管理层面的问题。技术、业务方面的问题只是表象。所以要解决数据质量的问题,不能仅从技术角度来解决问题,要从管理、业务、技术等多个方面共同发力。在解决数据质量问题之前,首先是要建立一套数据质量的评估标准。
数据质量评估标准
提及数据质量的时候,就必须有一个数据质量的评估标准,通过这个标准,才能知道依据什么来评估数据的好坏,才能知道数据质量的改进方向。因此,DAMA 提出了数据质量的六个核心维度。见下图
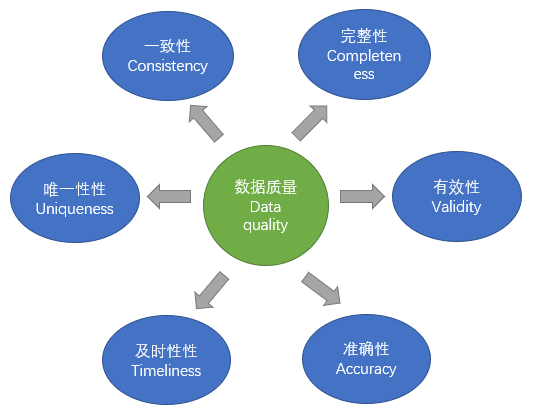
注:DAMA国际是一个全球性数据管理和业务专业志愿人士组成的非营利协会,致力于数据管理的研究和实践。自1988年成立以来,多年致力于数据管理的研究、实践及相关知识体系的建设,在数据管理领域累积了极为深厚的知识沉淀和丰富经验,并先后出版了《DAMA 数据管理字典》和《DAMA数据管理的知识体系和指南》(DAMA-DMBOK)数据唯一性:同一客观实体的数据是否存在重复记录。例如一位公民只能有唯一的身份证号码与其对应。数据完整性:数据是否存在缺失记录或者缺失字段。例如一位公民的基本信息中需要填写姓名、性别、籍贯、出生年月、民族等信息,但是该公民的信息中缺失了上述信息的一项或多项。数据及时性:数据的产生以及供给是否及时。例如一家店铺每天统计前一天的销售额数据,但是因为某些原因只能提供两天前的数据。数据有效性:数据是否满足用户定义的约束条件或者是否在一定的取值范围之内。例如公民的手机号码必须由11位数字组成。数据准确性:数据是否与其对应的客观实体特征保持一致。即数据的记录值与其真实值之间的接近度,也叫误差。误差越大准确性越低。例如一位男性公民的身份信息中的性别记录显示为女。数据一致性:同一实体同一属性的数据在不同的系统中是否一致。例如一位公民的婚姻状态在民政局和公安局的信息应当保持一致。
鸿程数据中台质量探测
江苏鸿程大数据研究院是一家由南京大学PASA大数据实验室学术带头人黄宜华教授及其团队牵头,组织成立的省级大数据技术创新企业,公司旗下研发的全流程数据治理与统一数据中台,旨在打造集数据接入,清洗治理、数据加工、质量管理、共享开放、数据服务为一体的智能化数据中台。针对数据质量问题,鸿程大数据研究院调研并深度集成了DolphinScheduler开源工作流任务调度平台。DolphinScheduler是一个开源的分布式易扩展的可视化DAG工作流任务调度系统。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。目前DolphinScheduler已经被IBM、阿里、腾讯、360 等 1000 多家公司生产上广泛使用。
· 高可靠性:去中心化的多 Master 和多 Worker 服务架构, 避免单 Master 压力过大,另外采用任务缓冲队列来避免任务过载
· 简单易用:所有流程定义都是可视化,通过拖拽任务可完成定制 DAG ,也可通过 API 方式与第三方系统集成, 一键部署
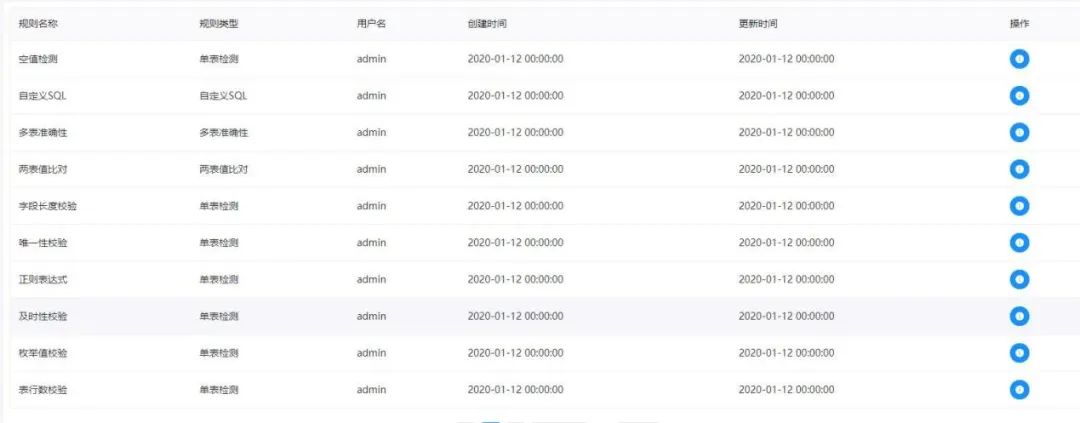
· 具有丰富的应用场景:支持多租户,支持暂停恢复操作. 紧密贴合大数据生态,提供 Spark, Hive, M/R, Python, Sub_process, Shell 等近20种任务类型· 高扩展性:支持自定义任务类型,调度器使用分布式调度,调度能力随集群线性增长,Master 和 Worker 支持动态上下线DolphinScheduler的数据质量模块,内置了多种数据质量规则,能够满足我们日常的数据质量检查需求,并且支持自定义SQL规则。详见下图。
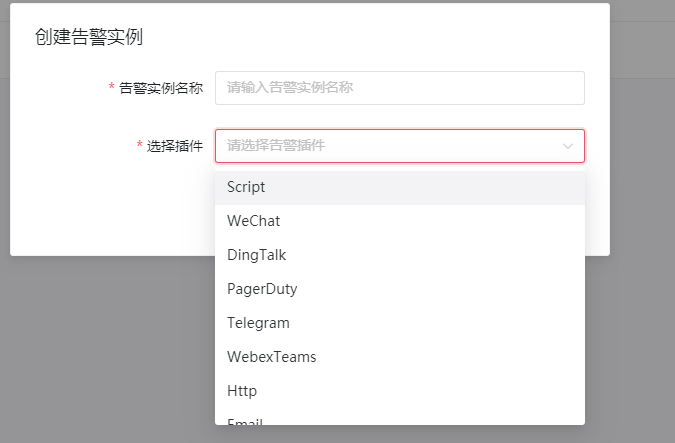
DolphinScheduler是一个分布式易扩展的可视化DAG工作流任务调度系统。可以无缝接入到工作流中,当出现严重的数据质量问题时,能够及时的告警和阻断,避免低质量的数据扩大影响。DolphinScheduler支持多种常见的告警插件,如钉钉通知,微信通知,脚本通知等。见下图
DolphinScheduler作为一个任务调度系统,不需要引进新的组件来执行调度任务。DolphinScheduler是一款优秀的开源组件,与本公司积极拥抱开源社区的观念相符。基于DolphinScheduler的数据质量检测案例
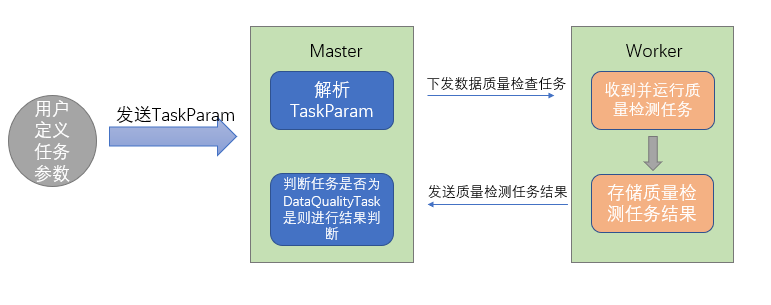
用户在界面定义任务,用户输入的值保存在TaskParam中,运行任务时,Master解析TaskParam,封装DataQualityTask所需要的参数下发至Worker。Worker运行数据质量任务,数据质量任务在运行结束之后将结果写入到指定位置,并将任务结果发送给Master,Master收到TaskResponse之后会判断任务是否为DataQualityTask,如果是的话会读取任务运行结果,并根据用户配置好的校验方式,操作符和阈值进行结果判断,如果结果为失败,再根据用户定义的失败策略进行告警或阻断。DolphinScheduler提供了多种校验方式,【Expected-Actual】期望值-实际值、【Actual-Expected】实际值-期望值、【(Expected-Actual)/Expected】(期望值-实际值)/期望值、【Actual/Expected】实际值/期望值;多种校验操作符:=,>、>=、<、<=、!=。
空值检查的目标是检查出指定列为空的行数,可将为空的行数与总行数或者指定阈值进行比较,如果大于某个阈值则判定为失败。
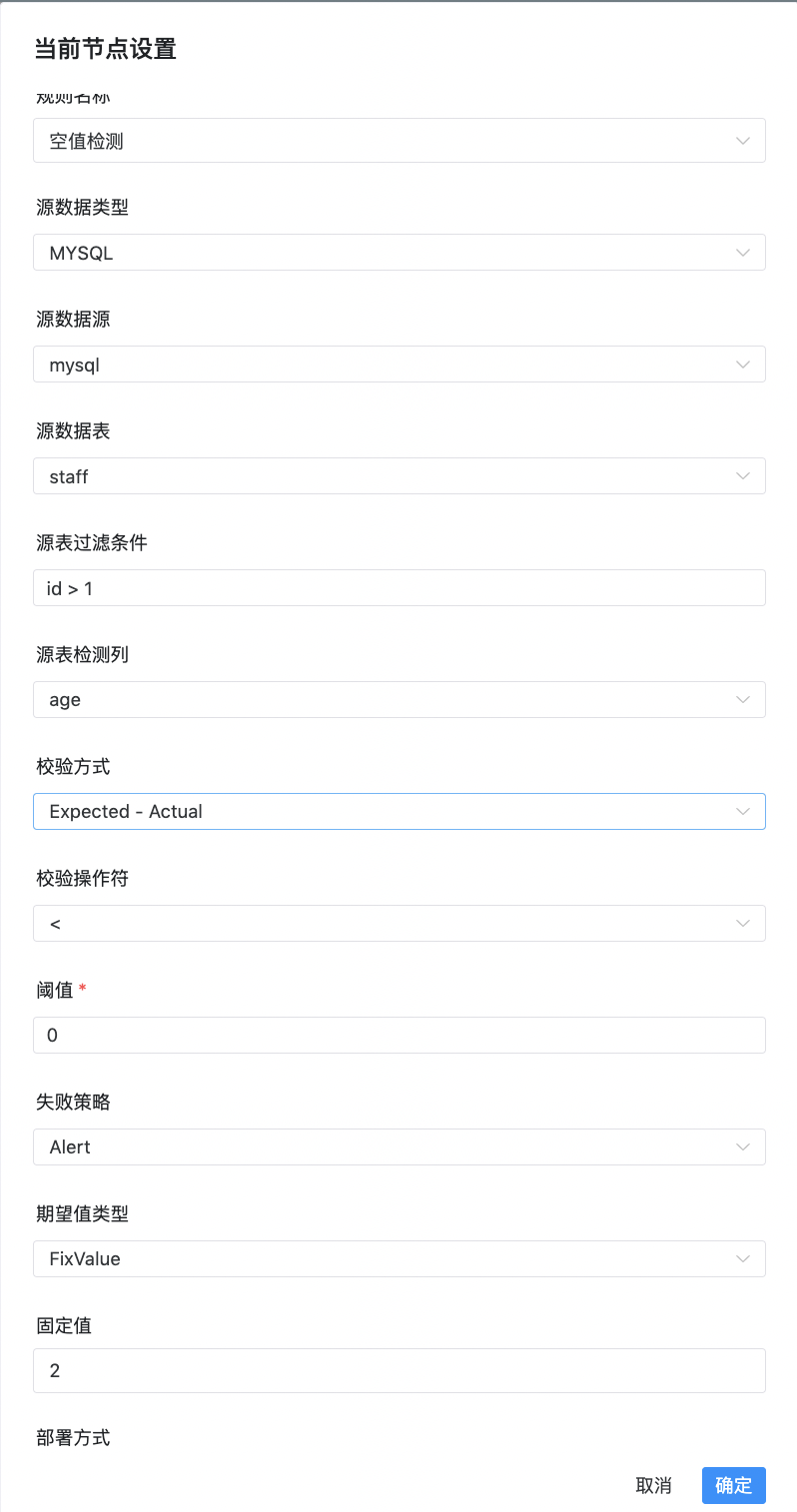
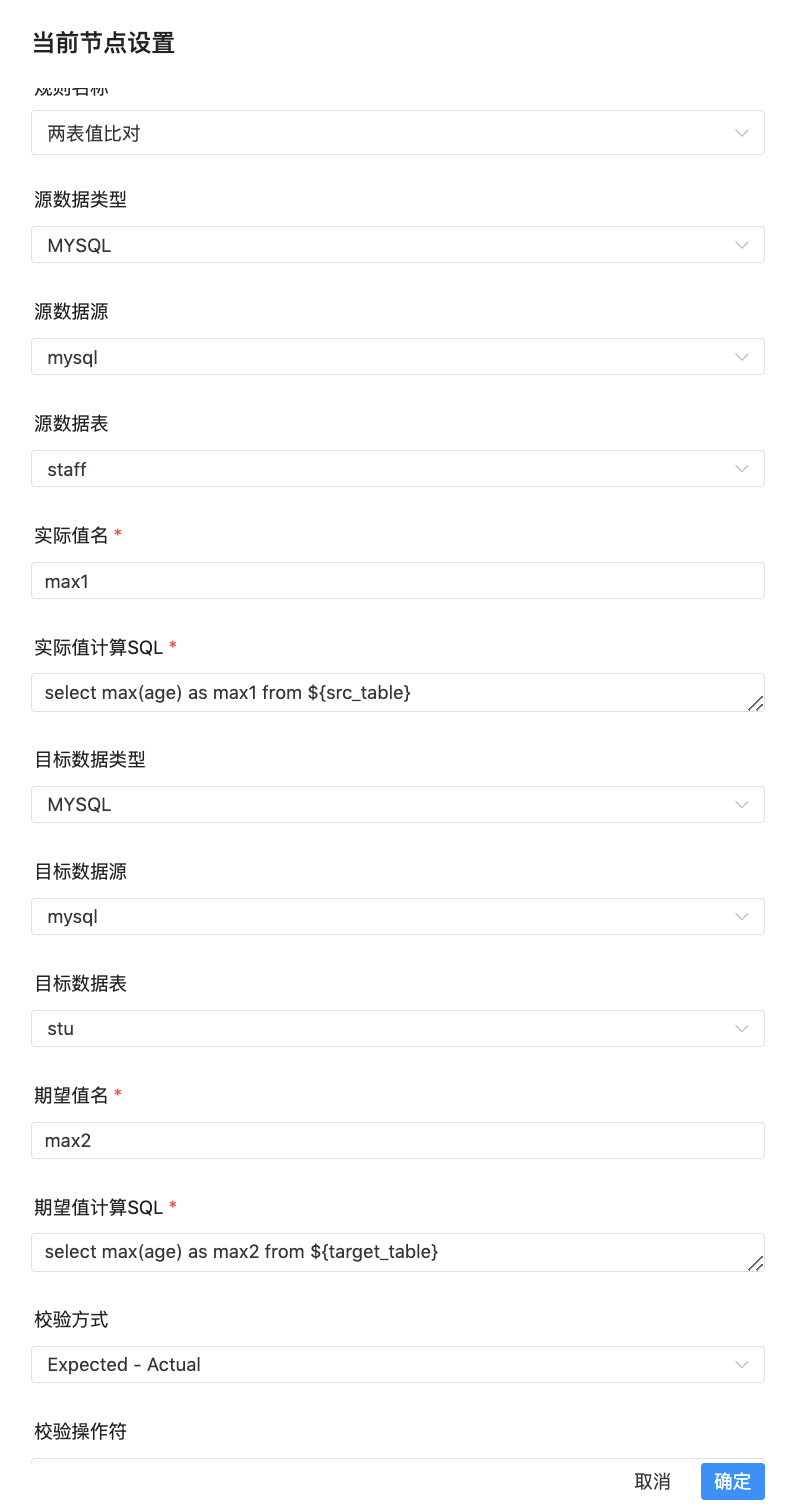
两表值比对允许用户对两张表自定义不同的SQL统计出相应的值进行比对,例如针对源表A统计出某一列的年龄的最大值max1,针对目标表统计出某一列的年龄的最大值max2,将max1和max2进行比较来判定检查结果。
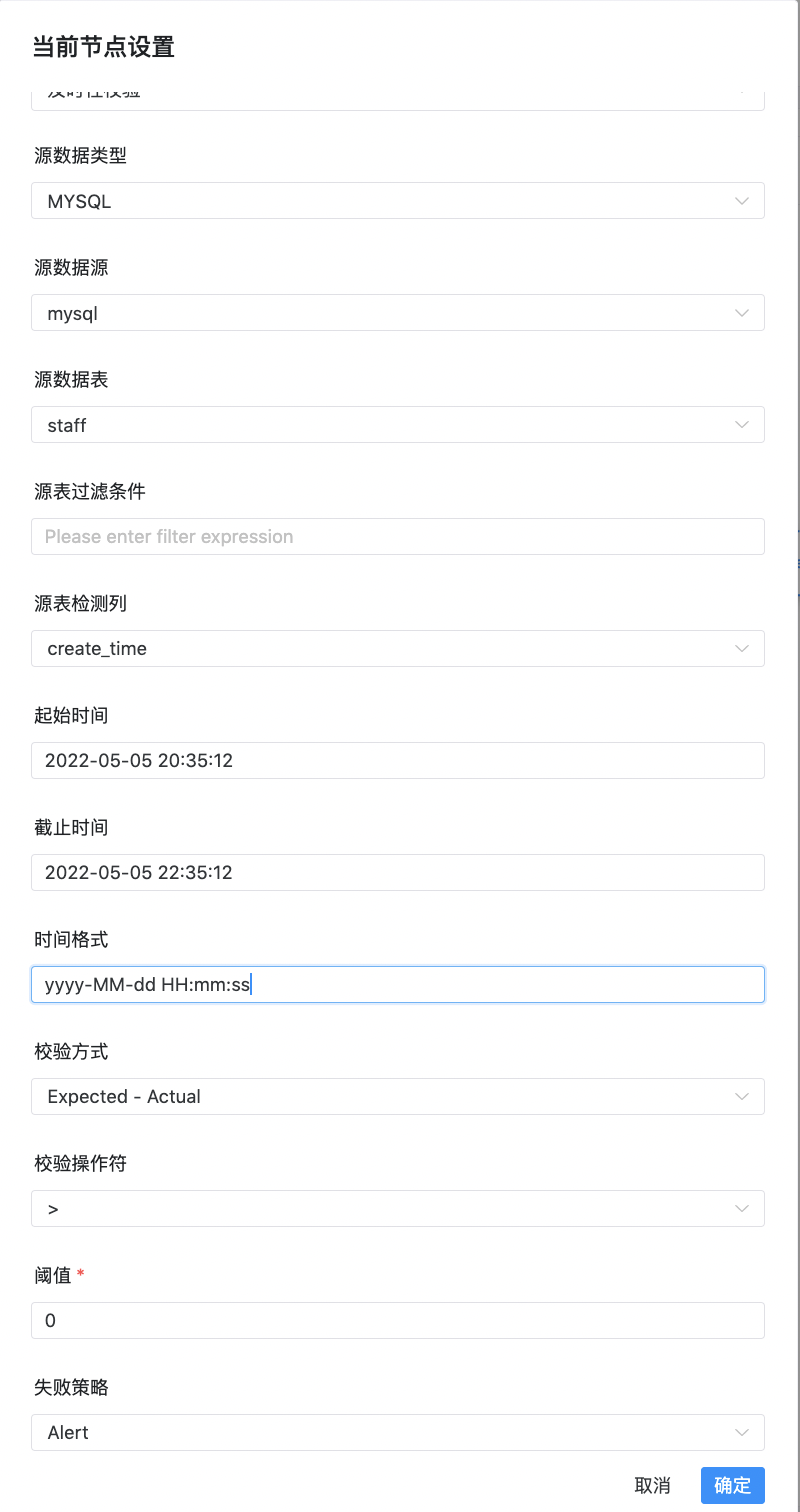
及时性检查用于检查数据是否在预期时间内处理完成,可指定开始时间、结束时间来界定时间范围,如果在该时间范围内的数据量没有达到设定的阈值,那么会判断该检查任务为失败。
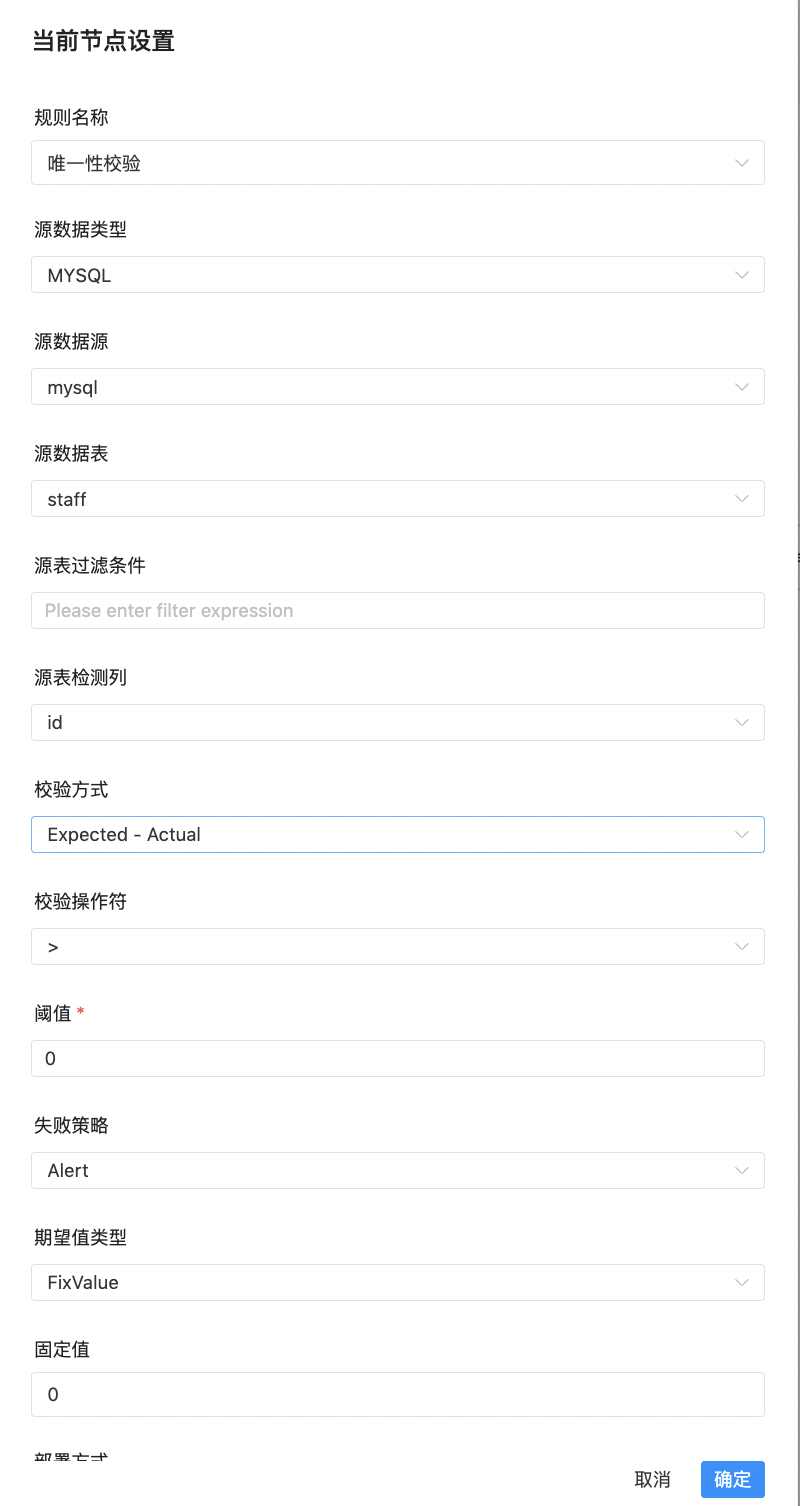
唯一性校验的目标是检查字段是否存在重复的情况,一般用于检验primary key是否有重复,如果存在重复且达到阈值,则会判断检查任务为失败。
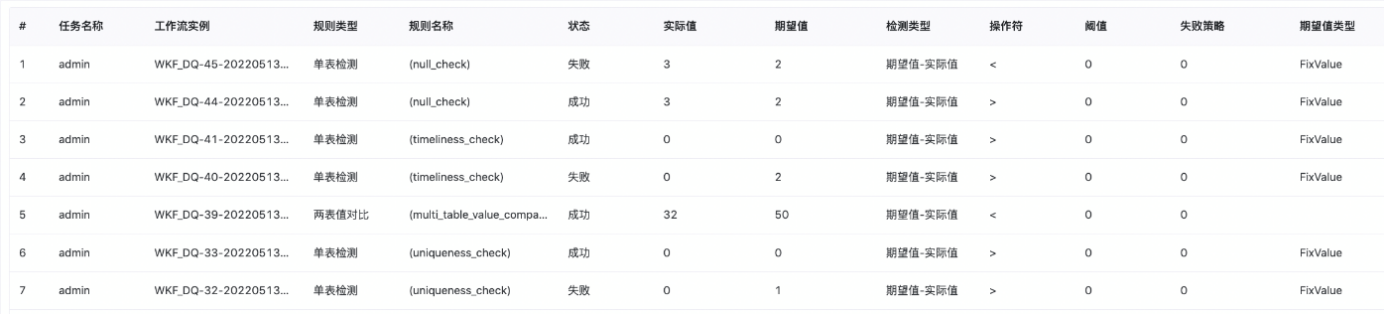
任务结果如下:
总结
本文介绍了数据质量概念、质量问题产生的原因和数据质量评估标准以及探索数据质量管理的一次探索。在数字经济和产业数字化转型的大背景之下,不断挖掘潜藏在海量数据中的价值成为了我们的必经之路。数据质量管理作为将数据用起来的前提条件,显得尤为重要。